
IPC: Qué es y por qué es tan importante en CPU y GPU
Seguramente que el IPC es uno de esos términos que has visto o escuchado en numerosas ocasiones. Si no sabes qué es y su importancia, en este artículo te explicamos todo lo que deberías conocer sobre este y otros términos tan importantes a la hora de elegir un procesador.
Índice de contenidos
¿Qué es el IPC? ¿Qué es el CPI?

Principalmente, cuando se estudia el rendimiento de una máquina se debe analizar desde el punto de vista del tiempo de respuesta (response time), es decir, el tiempo que se demora un procesador en ejecutar una determinada tarea o programa. Recuerda que explicamos que no todas las instrucciones tienen la misma duración, cada una puede tardar más o menos en función del tipo de instrucción. Por ejemplo, las más pesadas, como las de coma flotante, pueden tardar más ciclos en completarse, mientras las más ligeras tardarán menos.
Por tanto, esto se debe tener en cuenta a la hora de realizar cálculos de rendimiento basados en la productividad, como por ejemplo CPI (Cycles Per Instruction) y el IPC (Instructions Per Cycle). Diferente sería el cálculo del IPS (Instructions Per Second), ya que se basa en el segundo como magnitud de tiempo y ésta es siempre igual…
Como ya sabrás, las estrategias para aprovechar el incremento del número de los transistores se centran en dos principios: paralelismo y localidad. Y por eso estos términos son tan importantes para el rendimiento. Mientras mayor sea el IPC o IPS, mejor será el rendimiento del procesador. En cambio, el CPI o ciclos por instrucción debería ser lo más bajo posible, o próximo a 1. Mientras mayor sea el CPI, más mayor latencia de la instrucción.
Es decir, el paralelismo se ha aprovechado a través de la segmentación del cauce de procesamiento y a base de escalar el número de unidades funcionales o elementos de procesamiento, además de incluir nuevas unidades integradas como controladores DMA, E/S, etc., mientras que la localidad se manifiesta en una jerarquía de memoria con más niveles, acercando cada vez más información al núcleo de procesamiento y haciendo que ésta sea accesible en menor tiempo. Generando un modelo que se aproxima a:

Donde el tiempo que tarda en ejecutarse una tarea determinada es igual al número de instrucciones necesarias para dicha tarea (NI), por el número medio de ciclos necesarios para ejecutar cada instrucción (CPI) por el tiempo que tarda en producirse un periodo de reloj del procesador. Como el tiempo de ciclo es inverso a la frecuencia (1/f), entonces se puede realizar el ajuste de la fórmula para obtener la segunda fórmula que vemos.
Este modelo nos hace pensar sobre cómo podemos mejorar una arquitectura. Teniendo en cuenta que CPI depende del repertorio de instrucciones y la organización de la arquitectura de una máquina, NI depende del compilador y repertorio de instrucciones, y la frecuencia depende de la tecnología del chip y a la organización de un computador. Por tanto, la organización o jerarquización afecta tanto a CPI como a f, dejando ver que la explotación del rendimiento debe centrarse en el coeficiente CPI/f, haciendo que disminuya CPI y aumente la frecuencia.
El paralelismo puede ser a nivel de instrucciones, hebras (threads), procesos y bits. Si introducimos en la fórmula anterior la nueva variable del número medio de ciclos entre emisiones de instrucciones o CPE (Ciclos Entre Emisiones), así como el número medio de instrucciones que se emiten de una sola vez o IPE, entonces tendremos:
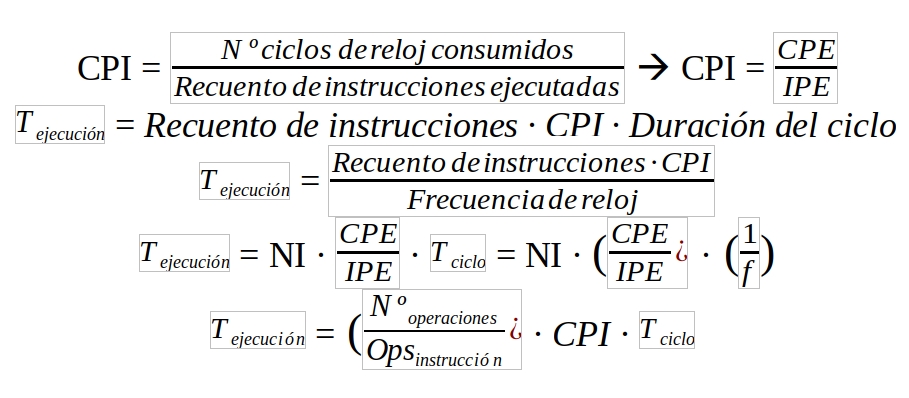
En una arquitectura segmentado y no superescalar, CPE = IPE = 1 y CPI = 1, mientras que en una superescalar CPE = 1 e IPE > 1, ya que en cada ciclo se emiten varias instrucciones. En cambio, en una arquitectura no segmentada tendríamos IPE = 1 y CPI = CPE > 1, ya que se emite una instrucción por cada ciclo máquina, éste ciclo máquina se compone a su vez por varios ciclos de reloj.
Cuando se produce una mejora de un factor x en la miniaturización de los componentes del circuito integrado, se obtiene una mejora con un factor en cuanto a superficie disponible para integrar más transistores. Eso supone que una mejoría en cuanto a la miniaturización de x supondría un incremento en la velocidad de conmutación del mismo orden. A mayor velocidad de conmutación, mayor frecuencia, y por tanto se reduce el CPI y se aumenta el IPE y/o se reduce el CPE.
¿Qué es el IPS? ¿Es igual que que IPC?

Hasta ahora hemos estado midiendo el tiempo de respuesta, pero también podríamos basar los cálculos de rendimiento en la cantidad de operaciones que puede realizar un procesador por unidad de tiempo, es decir, desde el punto de vista de la productividad (throughput). Entonces podemos hablar de otras magnitudes importantes para calcular el rendimiento, como los MIPS (Millions of Instructions Per Second), es decir, los millones de instrucciones que una CPU puede ejecutar en un segundo.
Para el cálculo de los MIPS nos podemos basar en las fórmulas anteriores para el cálculo de IPS, solo que corrigiéndolas para que nos den los millones de IPSs:

No es frecuente usar múltiplos o submúltiplos de esta magnitud, aunque a veces se haya hecho. Por ejemplo, los microprocesadores 8086 podían ejecutar 800 KIPS (a veces denominado TIPS por thousand IPS), es decir, 800.000 instrucciones por segundo. Tampoco es frecuente el uso de GIPS (Giga IPS)…
¿Sabías que? Linus Torvalds inventó los BogoMips (proviene de Bogus, que significa engañoso o incorrecto, y MIPS), una unidad de medida necesaria para el sistema de calibración de la temporización para GNU/Linux. Para ello se calcula la velocidad de procesamiento de un bucle de retardo y esa medida se coge como referencia.
El mayor inconveniente de usar los MIPS como una medida para el rendimiento es que solo es útil para comparar microprocesadores que usan el mismo conjunto de instrucciones y usando benchmarks compilados con un mismo nivel de optimización y un mismo compilador. De lo contrario sería bastante inexacta, debido a la longitud dispar de las instrucciones, frecuencias a las que se analiza, etc.

Si tenemos en cuenta los ciclos de detención debido a los conflictos:
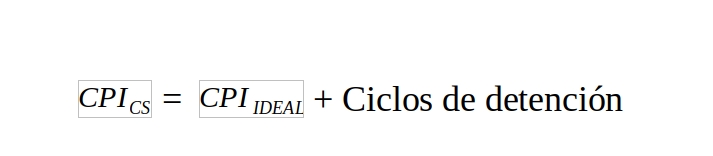
Es importante este último apunte sobre los cauces segmentados a la hora de calcular la aceleración como estudiaremos después. Una vez expresado este detalle, ya damos por finalizado el cálculo de MIPS.
¿Qué son los FLOPS?

Hay que considerar, que con los MIPS no se hacen distinciones entre operaciones enteras y de coma flotante, es decir, se miden las instrucciones por segundo de forma indiscriminada. Por ello surge la necesidad de otra unidad conocida como FLOPS (Floating-point Operations Per Second), es decir, el número de operaciones de coma flotante que puede realizar una CPU (también GPU, FPU, etc.) como bien sabes.

Además, si queremos realizar el cálculo para una unidad de procesamiento con varios núcleos y en sistemas MP podemos acudir a la fórmula (que también se podría usar de forma similar para los MIPS):
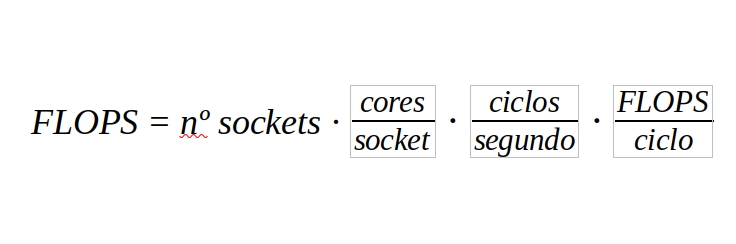
Es decir, la cantidad de sockets disponibles en la computadora, por la cantidad de núcleos diseñados por cada socket que existe, por la cantidad de ciclos por segundo que puede llegar a desarrollar y por las operaciones de coma flotante por cada ciclo.
En el caso de los FLOPS sí que se suelen usar múltiplos de ella debido al aumento de las capacidades de computo de las actuales máquinas.
Existen varios tipos de mediciones y en ocasiones puede llevar a confusión. Por ejemplo, un AMD Ryzen de primera generación puede realizar 8 DP FLOP por cada ciclo: un par de instrucciones FMA (2-wide). DP hace referencia a que se trata de coma flotante de doble precisión (64-bit), mientras que para la precisión simple o SP (32-bit) el valor sería diferente. En ese caso obtendríamos 16 SP FLOP por ciclo: un par de instrucciones FMA (4-wide).
También habría que diferenciar los FLOPS nativos y relativos, algo que también vale para los MIPS, aunque antes no lo haya citado. En el primer caso (nativos), se miden las operaciones o instrucciones de coma flotante por segundo que se realiza para un determinado programa. Este tipo de medida no es muy exacta, ya que dependerá del tipo de programa que se use para la prueba y de la computadora en sí. Algunos procesadores tienen un repertorio de instrucciones con pocas instrucciones específicas de coma flotante (ADD, SUB, MUL) valiéndose de ellas para realizar todo tipo de cálculos combinándolas, y otros usan más instrucciones para coma flotante (DIV, SQRT, EXP, SIN,…) permitiendo que se pueda realizar una operación específica con solo una instrucción. Es por eso que las medidas nativas no servirían más que para comparar máquinas iguales, surgiendo la necesidad de una medida relativa.
En el caso de medir relativos, o normalizados, se está indicando que se está calculando las operaciones de coma flotante por segundo teniendo en cuenta la equivalencia entre operaciones simples y complejas. Para ello se han creado tablas que hacen equivalencias entre las operaciones simples (ADD, SUB y MULT) que equivalen a un peso de 1 operación de coma flotante, las intermedias (DIV, SQRT,…) que tienen peso igual a 4 operaciones de coma flotante, y las más pesadas (EXP, SIN,…) con un valor de 8.
Por ejemplo, si tenemos un programa con las siguientes instrucciones: ADD, SUB, MUL, DIV, EXP, SIN, SQRT. En el sistema nativo se tratarían todas por igual (7), y en el sistema relativo el peso de todas ellas sería igual a 27, permitiendo una medida de rendimiento no tan dependiente del conjunto de instrucciones que tenga la máquina y más exacta para comparar rendimiento entre computadoras diferentes.
Las fórmulas anteriores estaban aplicadas al cálculo de los FLOPS nativos, por tanto, para el cálculo de los relativos habría que hacer esos ajustes por cada instrucción. Es decir, habría que analizar el programa que se va a usar como referencia para el cálculo y contabilizar sus instrucciones aplicándole el factor adecuado… Por tanto, la fórmula para el cálculo de los normalizados quedaría así:
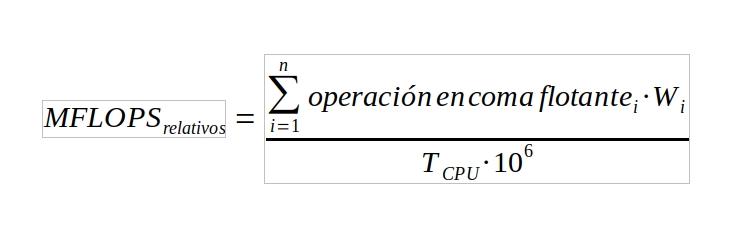
Donde i es uno de los n tipos de instrucciones en coma flotante con un coste veces mayor que el de una instrucción de coma flotante menos costosa. Es decir, indicaría el peso.
En ocasiones, aunque es bastante menos frecuente, también se suele usar la unidad MACS (Multiply-Accumulates Per Second). Podría ser especialmente interesante en ciertos procesadores como los DSP o para aplicaciones donde este tipo de operaciones son especialmente frecuentes. En este caso simplemente habría que medir la cantidad de operaciones de este tipo por unidad de tiempo…
Ahora ya conoces algo más acerca de las unidades de media de rendimiento de tu CPU como es el IPC. ¿Has aprendido mucho con este artículo? ¡Esperamos tus comentarios sobre este tema de IPC!
