
La pipeline es algo que muchos han escuchado sobre ello, especialmente si leen sobre las características técnicas de las unidades de procesamiento como la CPU o la GPU. Pero no todos saben qué es realmente, cómo influye en el rendimiento, y cómo funciona…
Índice de contenidos
¿Qué es la Pipeline?
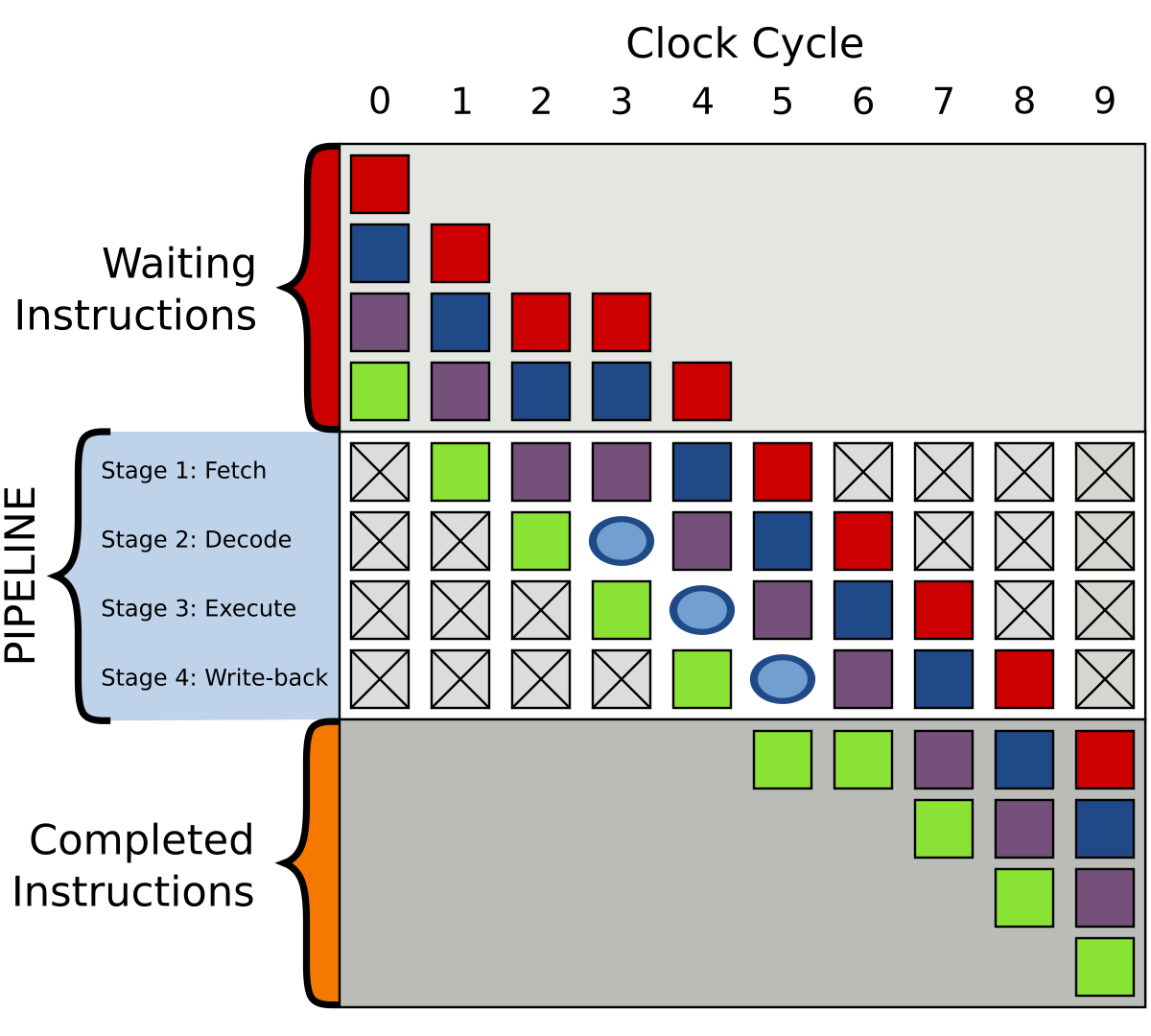
La pipeline (o canalización) consiste en descomponer la ejecución de una instrucción en una serie de pasos o etapas, donde cada etapa realiza una tarea específica. Estas etapas están conectadas por registros intermedios que almacenan los datos y el estado necesarios para transferir información entre una etapa y la siguiente.
Imagina que una instrucción que entra en la unidad de procesamiento tiene que pasar una serie de pasos para procesarse. Por ejemplo, tiene que ser buscada, decodificada, y la unidad de ejecución, como la ALU o la FPU, debe ejecutar la operación implícita en ella sobre los datos u operandos. En un procesador sin pipeline, hasta que todo ese proceso no termina, no entraría la siguiente instrucción, como ocurría en el pasado.
Con la implementación de la pipeline, se puede subdividir ese proceso en varias etapas individuales, desconectadas la una de la otra, para que cada una actúe de forma independiente. Por ejemplo, en este caso, una unida Fetch podría buscar la instrucción a ejecutar y almacenar esta instrucción en un registro, una vez almacenada, ya puede dedicarse a buscar la siguiente…
El siguiente paso, la decodificación, puede coger la primera instrucción del registro y comenzar a decodificarla, almacenando el resultado en otro registro. Y una vez acabado este paso, puede comenzar a decodificar la siguiente instrucción sin necesidad de esperar…
Y así sucesivamente, es decir, sin necesidad de que la instrucción termine todo el ciclo para comenzar con la siguiente, lo que aumenta el rendimiento, especialmente si se consigue que cada etapa se pueda ejecutar en un solo ciclo de reloj. Ten en cuenta que al ejecutar varias instrucciones simultáneamente, la pipeline mejora la utilización de los recursos del procesador e incrementa el throughput.
Un ejemplo de aceleración con pipeline, podría ser el siguiente. Imagina una CPU simple, sin pipeline, que ejecuta una instrucción en 5 ciclos de reloj y tiene que ejecutar un programa que consta de 100 instrucciones:
Tiempo total=5×100=500 ciclos
Con esa misma CPU con una pipeline de 5 etapas, después de un tiempo de llenado inicial (4 ciclos), cada nueva instrucción se completa en un ciclo adicional:
Tiempo total=5+(100−1)=104 ciclos
Esto muestra una mejora significativa en el throughput…
También deberías leer sobre los mejores procesadores del mercado
Implementación de la Pipeline: Registros Entre Etapas
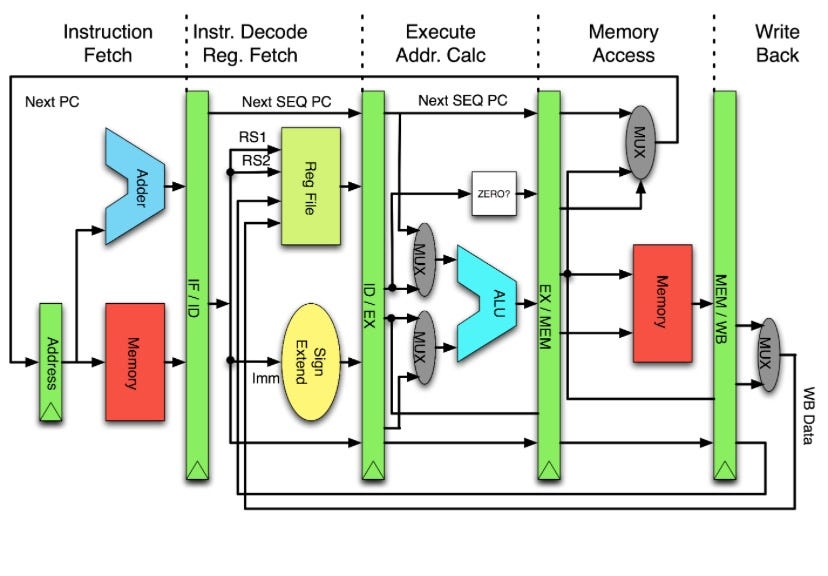
Como ya puedes imaginar por mi explicación anterior, la implementación de una pipeline requiere dividir el hardware del procesador en bloques funcionales independientes que trabajen en paralelo. Entre cada bloque, se colocan registros intermedios que almacenan temporalmente los resultados parciales de las etapas anteriores. Estos registros aseguran que los datos necesarios para la siguiente etapa estén disponibles al comienzo de cada ciclo de reloj.
Estos recursos pueden contener diversa información, como puede ser instrucción en curso, datos de los operandos necesarios sobre los que habría que aplicar la operación (aunque depende del tipo de direccionamiento o modo en el que trabaje la CPU), así como información de control para etapas siguientes, etc.
Estos registros se suelen actualizan al final de cada ciclo de reloj, permitiendo que cada etapa procese una nueva instrucción al mismo tiempo que las demás continúan trabajando en las instrucciones anteriores.
Te deberías leer nuestra guía sobre las mejores tarjetas gráficas del mercado
A pesar de que parece sencilla de implementar a nivel físico, lo cierto es que surgen una serie de problemas y retos en el diseño de pipelines, especialmente si se quiere garantizar que funcione de forma correcta y eficiente:
- Dependencias de datos: ocurren cuando una instrucción necesita un dato que aún no está disponible porque está siendo calculado por otra instrucción anterior en la pipeline. Para solucionarlo, se utilizan técnicas como el bypassing/forwarding, que permiten redirigir el resultado calculado en una etapa posterior directamente a una etapa anterior que lo necesita.
- Dependencias de control: aparecen cuando hay instrucciones de salto o bifurcación que alteran el flujo de ejecución. Para esto se implementan técnicas como predicción de saltos, que intenta predecir el destino del salto antes de que se calcule realmente.
- Dependencias estructurales: ocurren cuando dos o más etapas de la pipeline intentan acceder al mismo recurso al mismo tiempo, como la memoria o la ALU. Se puede duplicar hardware crítico o utilizar estrategias para resolver conflictos, como insertar ciclos de espera (burbujas).
Cuántas etapas tienen las pipelines modernas

El número de etapas en una pipeline depende del diseño del procesador, y no solo está presente en las CPUs, también en otros tipos de procesadores, como las GPUs. Por ejemplo, podemos encontrar algunos procesadores RISC como los ARM Cortex-M o MIPS que pueden tener de 3 a 5 etapas, ya que se enfocan en la eficiencia energética y simplicidad del núcleo. Otros diseños de alto rendimiento, como los propios de Intel o AMD, son unidades hipercanalizadas, es decir, con pipelines más profundas, con entre 14 y 20 etapas. Algunas microarquitecturas, como la NetBurst de los Pentium 4 llegaron a tener hasta 31 etapas, aunque eso produjo problemas de latencia y eficiencia, por lo que en los siguientes diseños se simplificaron.
En los casos sencillos suelen ser etapas como Fetch, Decode, Execution, etc., y que son las que se suelen usar como ejemplo para enseñar qué es una pipeline. Pero seguro que te estás preguntando qué son las etapas cuando hay tantas como en los diseños de alto rendimiento. Pues bien, por ejemplo, algunos diseños de Intel o AMD, de por ejemplo 16, etapas, se podrían descomponer en las siguientes etapas:
- IF1 (Instruction Fetch, Parte 1): inicio del acceso a la memoria para recuperar la instrucción desde la caché de instrucciones (L1 I-cache).
- IF2 (Instruction Fetch, Parte 2): completar el acceso a la memoria e identificar la dirección de la siguiente instrucción.
- Branch Prediction: predicción del resultado de bifurcaciones utilizando hardware especializado como el Branch Target Buffer (BTB) y el Branch Predictor.
- Instruction Buffering: las instrucciones recuperadas y decodificadas parcialmente se almacenan en un buffer para gestionar dependencias y orden.
- ID1 (Instruction Decode, Parte 1): decodificación inicial para determinar el tipo de instrucción (aritmética, memoria, control, etc.).
- ID2 (Instruction Decode, Parte 2): decodificación más detallada y extracción de operandos de los registros (renombrados si es necesario).
- Micro-op Translation: traducción de instrucciones complejas (CISC) en operaciones más simples (micro-ops), típicas de arquitecturas x86 modernas.
- Dispatch: envío de las micro-ops a las unidades funcionales disponibles para su ejecución.
- Register Allocation: asignación de registros físicos a las instrucciones para el almacenamiento temporal de datos.
- Issue: lanzamiento de las micro-ops a la unidad funcional correspondiente (ALU, FPU, etc.) en base a su disponibilidad.
- EX1 (Execute, Parte 1): ejecución inicial en la unidad funcional. En el caso de operaciones complejas, esta etapa puede descomponerse aún más.
- EX2 (Execute, Parte 2): finalización de la ejecución de la operación. Si se trata de operaciones de memoria, se calcula la dirección efectiva.
- MEM1 (Memory Access, Parte 1): inicio del acceso a la memoria para instrucciones de carga/almacenamiento.
- MEM2 (Memory Access, Parte 2): completar el acceso a la memoria (lectura de caché o escritura).
- Writeback: los resultados de las operaciones se escriben en los registros físicos o en la memoria si es necesario.
- Retire/Commit: verificación del orden y confirmación de que las instrucciones se completaron correctamente; los resultados se comprometen al estado arquitectónico del procesador.
Algo parecido pasa en otros diseños RISC, como puede ser el ARM Cortex-A (Cortex-A7, Cortex-A53, Cortex-A76, etc.), en los que el número de etapas en el pipeline varía, pero generalmente está entre 8 y 15 etapas, con diseños más modernos acercándose a las 15 etapas para soportar frecuencias más altas y capacidades de ejecución más complejas.
Como he dicho, las GPUs también pueden tener pipeline. Todas las unidades modernas tienen de hecho, como las de NVIDIA o AMD, entre otras. Esto se debe a su enfoque en tareas altamente paralelizables, como el procesamiento gráfico y la computación de alto rendimiento (HPC) cuando se usa en modo GPGPU. El número de etapas puede variar, pero suelen tener entre 25 y 30 etapas debido a la complejidad de las tareas gráficas. Por ejemplo, podrían ser etapas como:
- Vertex Fetch: recuperación de vértices desde la memoria.
- Vertex Shading: aplicación de transformaciones geométricas, iluminación, y cálculo de vértices.
- Primitive Assembly: construcción de primitivas (triángulos, líneas) a partir de los vértices.
- Tessellation: división de primitivas en partes más pequeñas para aumentar el detalle.
- Geometry Shading: modificación de geometrías para efectos complejos.
- Rasterization: conversión de primitivas geométricas a fragmentos (pixeles potenciales).
- Fragment Shading (Pixel Shading): cálculo del color, textura y efectos para cada fragmento.
- Early Z-Test: determinación inicial de la visibilidad de fragmentos (z-culling).
- Texturing: aplicación de mapas de textura a los fragmentos visibles.
- Late Z-Test: confirmación de visibilidad tras el shading.
- Blending: mezcla de fragmentos con valores existentes en el framebuffer para efectos como transparencia.
- Output: escritura del resultado final en el framebuffer o VRAM.
Tipos de pipeline modernas
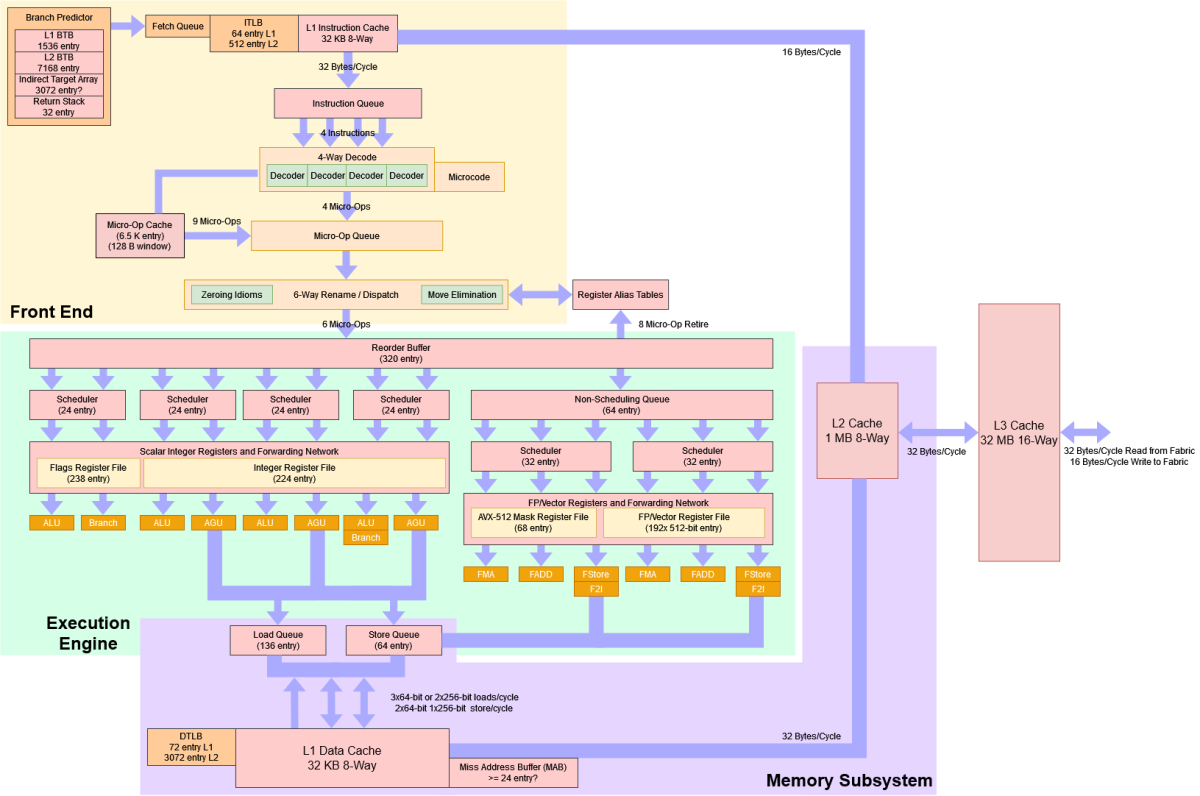
Los procesadores modernos no solo utilizan una pipeline simple, sea de las etapas que sea, sino que implementan técnicas avanzadas para maximizar su rendimiento:
- Pipelines superescalares: permiten ejecutar múltiples instrucciones en paralelo al incluir varias pipelines independientes dentro de un mismo núcleo. Y eso se debe a que multiplican el número de unidades funcionales, como por ejemplo incluir 3 ALUs en vez de solo una…
- Pipeline dinámica (Out-of-Order Execution): permite que las instrucciones se ejecuten fuera de su orden original siempre que no violen dependencias de datos, reduciendo tiempos de espera. Para ello, se necesitará también un ROB o buffer de reordenamiento para las resultados.
- SMT: como sabes, dividen la pipeline entre varios hilos de ejecución para maximizar la utilización de recursos.
- Vectorización: procesadores modernos integran unidades SIMD (Single Instruction, Multiple Data) que amplían las capacidades de la pipeline para procesar vectores completos en una sola instrucción.
Es más, las nuevas unidades no solo usan una de esas técnicas, sino que los actuales diseños de ARM, Intel, AMD, etc., son un todo en uno, ya que tienen pipeline, son superescalares, con ejecución fuera de orden, implementan SMT, y unidades vectoriales.
No todo es positivo, la pipeline también tiene desventajas

Aunque las pipelines son extremadamente eficientes y aumentan el rendimiento, tienen limitaciones intrínsecas:
- Latencia de llenado: antes de que la pipeline alcance su máxima eficiencia, necesita llenarse completamente, lo que introduce latencia inicial.
- Desempeño en instrucciones no secuenciales: saltos frecuentes o dependencias de control pueden reducir drásticamente el rendimiento.
- Ley de Amdahl: no todas las partes de un programa pueden paralelizarse. Incluso con una pipeline eficiente, la mejora total del sistema está limitada por las secciones secuenciales.
- Complejidad: por supuesto, el diseño se hace más complejo y caro, no solo por la inclusión de registros intermedios, sino porque para que todo funcione de forma correcta, complica más el circuito final.
Afortunadamente, se han implementado gran cantidad de mejoras para que estas desventajas prácticamente sean despreciables, y que sus ventajas sean muy notables. Además, las mejoras en la ejecución especulativa o mejora en la predicción de saltos, así como las pipelines heterogéneas, el DVFS, y la IA, están ayudando mucho en este sentido.
Deja tus dudas o comentarios…






