Annapurna Labs, una división de AWS (Amazon Web Services) es la diseñadora de los procesadores Graviton. Unos chips con un gran rendimiento para HPC y que no demasiados conocen. Por eso, vamos a introducirnos de lleno en estas CPUs tan interesantes y que puedes usar tú mismo si quieres a través de los servicios de la nube de Amazon.
Sin ir más lejos, puedes usar instancias con sistema operativo RHEL, Ubuntu, SLES, etc., y entre los más de 475 tipos de instancias EC2 que tiene AWS, las que utilizan chips Graviton son:
Índice de contenidos
Annapurna Labs, la división de AWS, es la encargada de diseñar la microarquitectura del Graviton basándose en ARM de 64-bit. Concretamente, hasta la fecha, han lanzado 3 versiones:
Ahora vamos a ver un poco más en profundidad a Graviton3 o la tercera generación de Graviton, para eso, nos vamos a detener en los siguientes puntos:
Graviton 3 era un diseño chiplets, todo lo contrario que las dos generaciones anteriores que eran chips monolíticos. Además de eso, hay que destacar:
Aquí te muestro la microarquitectura Arm Neoverse V1 que la compañía licencia y también el diagrama de la microarquitectura del Graviton 3, para que aprecies cuáles fueron las modificaciones introducidas por Annapurna Labs. Y ahora pasamos a desgranarlas:
El predictor de ramas es una de las partes más importantes en una microarquitectura, ya que cuando no es eficiente o preciso, se necesitará limpiar el cauce de la pipeline en caso de fallo de predicción (el fallo introduce lo que se denominan burbujas), lo que significará bastantes ciclos de penalización. Aunque en la microarquitectura V1 se ha mejorado este predictor de ramas con respecto al Neoverse N1, Annapurna Labs ha optado por modificar el preditor para el Graviton 3 y hacerlo más parecido al del Intel Ice Lake SP.
Además, es algo más simple que el predictor del AMD EPYC Zen 3 (Milan), ya que usa un nivel en vez de dos, aunque puede reconocer patrones de ramas muy largos, de hasta 512 ramas, además de ser más rápido.
Por otro lado, el Graviton 3 también ha apostado por una configuración BTB (Branch Target Buffer) de bastante rendimiento con hasta 4K entradas en el principal y un L2 BTB que podría llegar a 10K de entradas. Esto permite gestionar los saltos con un impacto en los ciclos de reloj muy bajo, así como manejar dos tramas por cada ciclo de forma simultánea. De este modo, el Graviton se pone a la par de la microarquitectura Intel Golden Cove para los núcleos P-Core de Rocket Lake, aunque la del Graviton supera incluso a la de Intel.
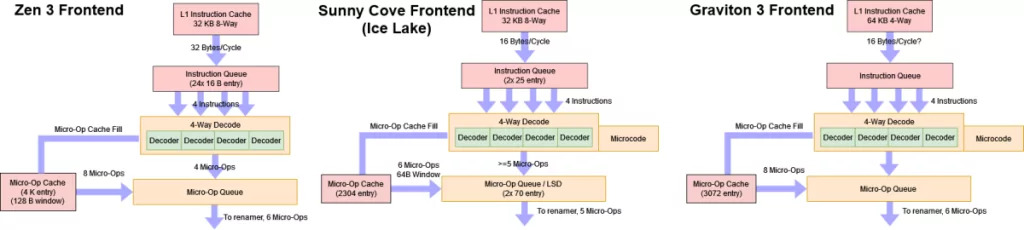
Lo siguiente, vamos al Front-End de la microarquitectura, es decir, la parte en la que se reciben las instrucciones, se decodifican y se envían las microoperaciones a las unidades de ejecución para que las ejecuten. En la imagen superior puedes ver una comparativa de esta parte en tres microarquitecturas, como la AMD Zen 3, Intel Sunny Cove (Ice Lake) y en el Graviton 3.
Como se puede apreciar, en el Graviton 3 se ha usado un esquema similar a los de Intel y AMD, alejándose un poco de la Neoverse V1 en la que se basa este chip. Como puedes ver, se ha implementado una caché de microoperaciones, haciendo que se tenga un ancho de banda de capacidad de recuperación de instrucciones similar al del AMD Zen 3, con hasta 6 IPC (Instructions Per Cycle).
También se puede apreciar que el Graviton 3 ha creado colas de recuperación más largas, lo que hace que se pueda usar un ciclo fetch más agresivo.
Para poder mejorar el rendimiento, muchas microarquitecturas modernas usan una técnica denominada renombre de registros. En este sentido, Graviton 3 ha usado un diseño muy similar al AMD Zen 3. Pese a eso, el Graviton 3 aún está por debajo de los resultados obtenidos por Intel y AMD, como puedes ver en esta tabla:
| Graviton 3 | Ampere Altra (Neoverse N1) | Intel Ice Lake (Sunny Cove) | AMD Zen 3 | |
| MOV independiente r,r | 3.81 | 2.86 | 4.77 | 5.72 |
| MOV dependiente r,r | 1.36 | 1.38 | 4.76 | 5.7 |
| XOR/EOR r,r | 1.00 | 1.00 | 3.81 | 5.72 |
| MOV r, 0 | 5.71 | 3.63 | 3.82 | 3.81 |
| SUB r, r | 1.00 | 1.00 | 3.81 | 5.7 |
Las limitaciones en el caso del Graviton 3 podrían estar también relacionadas con el número limitado de puertos de las unidades de ejecución, ya que más puertos implica un diseño más complejo, y se ha optado por un diseño algo más sencillo. No obstante, lo que sí es mejor en Graviton 3 con respecto a Ice Lake es que no rompe ciertas dependencias, por lo que se parecería más al AMD Zen 3 en ese sentido.
La totalidad de CPUs de alto rendimiento actuales usan el paradigma de la ejecución fuera de orden, conocida en inglés como OoOE (Out-of-Order Execution). Esto quiere decir que la CPU no ejecutará las instrucciones en el orden en el que están en el programa, de forma secuencial, sino que lo hará de forma desordenada dependiendo de la disposición de los datos, acelerando así el rendimiento.
En este caso, se necesita un ROB (Reorder Buffer), es decir, un buffer de reordenamiento para ir reordenado estas operaciones de forma adecuada para la ejecución del programa. Aunque no hay detalles, podría ser un ROB de 512 entradas, lo que sería superior a los de Intel y AMD.
Por otro lado, el archivo de registro de los RISC es bastante grande, y prueba de ello es el del Graviton 3. Esta microarquitectura usa unos 125 registros vectoriales de 256-bit de longitud, para poder guardar los datos de instrucciones como las SVE o dos de NEON (128-bit).
En cuanto a la cola de carga, parece que Annapurna Labs ha optado por un diseño más parecido al AMD Zen 2 o Zen 3.
El planificador (scheduler), es otro elemento muy importante en una microarquitectura, ya que se encargará de planificar las operaciones que debe procesar la CPU. No se han dado demasiados detalles al respecto, pero según algunas pruebas de ingeniería inversa podría ser similar al Intel Ice Lake y AMD Zen 3, con gran cantidad de entradas para operaciones más frecuentes:
| Entradas del planificador del Graviton 3 | ||
| Suma de enteros | 81 | |
| Multiplicación de enteros | 44 | |
| Rama (no tomada) | 43 | |
| Multiplicación y bifurcación de enteros alternos | 82 | |
| Sumador escalar FP | 54 | |
| Multiplicar escalar FP | 54 | |
| Suma y multiplicación FP alternas | 54 | |
| Suma SVE FP de 256 bits | 56 | |
| Convertir entero a coma flotante (FP) | 22 | |
| Store, Dependencia de dirección | ¿28? | |
| Store, Dependencia de datos | ¿28? | |
| Load | ¿54? | |
| Load/Store alternativo, dependencia de dirección | ¿54? |
También es importante analizar el Back-End, es decir, la otra gran parte junto al Front-End. Esta otra parte de la microarquitectura de la CPU es la que se encarga de las ejecuciones, es decir, la que tiene las unidades de ejecución como pueden ser las ALUs, FPUs, etc. Estas son las que reciben las microoperaciones con las operaciones lógicos o aritméticas que deben aplicar a los datos.
En el caso del Graviton 3 nos encontramos con hasta 4 ALUs (Arithmetic-Logic Unit) para números enteros, es decir, una más que la Neoverse, además de agregar una pipeline de memoria de factor 3 frente a las 2 de Neoverse.
Por otro lado, también tenemos FPUs (Floating Point Units) para coma flotante y ejecución vectorial (SIMD). Consisten en unidades para realizar sumas y multiplicaciones con coma flotante para instrucciones SVE de 256-bit que pueden ejecutarse en solo 2 ciclos de reloj, lo cual es bastante rápido. Una gran mejora en cuanto a latencia frente al Neoverse. De hecho, las mejorias lo han posicionado mejor que los de AMD e Intel, con menor penalización de ciclos de reloj:
| Operación | Graviton 3 | Neoverse N1 | AMD Zen 3 | Intel Ice Lake SP (Sunny Cove) |
| Suma FP | 2 | 2 | 3 | 4 |
| Multiplicación FP | 3 | 3 | 3 | 4 |
| FP Fusionado Multiplicar+Suma (FMA) | 4 | 4 | 5 | 4 |
| Suma de enteros vectoriales | 2 | 2 | 1 | 1 |
| Multiplicación de enteros vectoriales | 4 | 5 | 3 | 10 (debido a AVX-512 de 512-bit) |
Para finalizar, no hay que olvidar el subsistema de memoria de esta CPU Graviton 3. En este chip podemos apreciar que cuenta con:
Además, el Graviton 3 usa controladores integrados (en chips IO separados dentro del empaquetado, lo que penaliza un poco en cuando a velocidad de acceso en comparación con un chip monolítico) de memoria tipo DDR5, con peores latencias que la DDR4, como bien sabes, pero compensa el rendimiento. Concretamente, las pruebas han revelado que el Graviton 3 tiene un tiempo de acceso a la memoria principal de 10ns más lento que el AMD Zen 3.
También te interesará conocer cuáles son los procesadores más potentes del mercado actual
La tarjeta gráfica RTX 5060 Ti todavía no ha sido anunciada, pero ASUS revela accidentalmente…
En esta guía te voy a explicar cómo desactivar la función para compartir tu ubicación…
Si quieres llevar su almacenamiento portable de alta velocidad y con estilo, Asus Cobble SSD…
{kind=link}
{kind=link}
{kind=link}
{kind=link}