Intel ya ha coqueteado con el mundo de la GPU durante décadas atrás, pasando por sus primeras iGPUs hasta llegar a las actuales tarjetas gráficas dedicadas que esta firma se ha atrevido a lanzar al mercado. No obstante, aún está a años luz de sus competidores, AMD y NVIDIA, por lo que solo puede competir en precio y con la gama más baja de sus contrincantes.
Pero ¿por qué motivo está tan lejos? ¿qué diferencia a esta arquitectura de GPU respecto a las de NVIDIA y AMD? ¿se parece en algo? Todo eso lo vamos a analizar en este artículo, para que puedas saber más acerca de ello. Además, así podrás conocer si realmente Intel podría ponerse al día y alcanzar a sus contrincantes en un futuro…
Índice de contenidos
Para este análisis, pondremos de ejemplo la arquitectura Intel Xe de las Arc.

Como sabes, NVIDIA emplea lo que se denomina SM o Streaming Multiprocessors, mientras que AMD lo denomina CU o Compute Unit. En el caso de Intel puede aparecer como Execution Unit o EU en algunas arquitecturas o como Vector Engine.
Para comprender las diferencias de la organización o arquitectura de la GPU Intel respecto a sus contrincantes, hay que comenzar por estas unidades de ejecución, que serán las unidades de sombreado o shader básicas. Estas unidades están diseñadas como un pequeño procesador o unidad FPU vectorial para agregar paralelismo a nivel de hilo o thread (TLP).
Es decir, más que una simple unidad de cálculo, tienen algunos componentes extras como puede ser una unidad de control propia, registros propios, y sus unidades de ejecución correspondientes. En definitiva, se parecen más a un núcleo de CPU que a una FPU simple. De hecho, podemos ver que en la arquitectura de Intel se usan 4 FPUs de FP32, es decir, de coma flotante de precisión simple o 32-bit que funcionan como unidades SIMD o vectoriales. También tenemos otras 4 ALUs para enteros conmutadas, y soportan SIMD sobre registro.
Gracias a que se opera sobre registros, es decir, que se subdividen las unidades de cálculo, se puede trabajar con el doble de operandos por cada ciclo de reloj. Por ejemplo, se puede trabajar con FP32 pero también con dos FP16 a la vez o cuatro FP8 por ciclo. Y así es como se ejecutan los programas Shader.
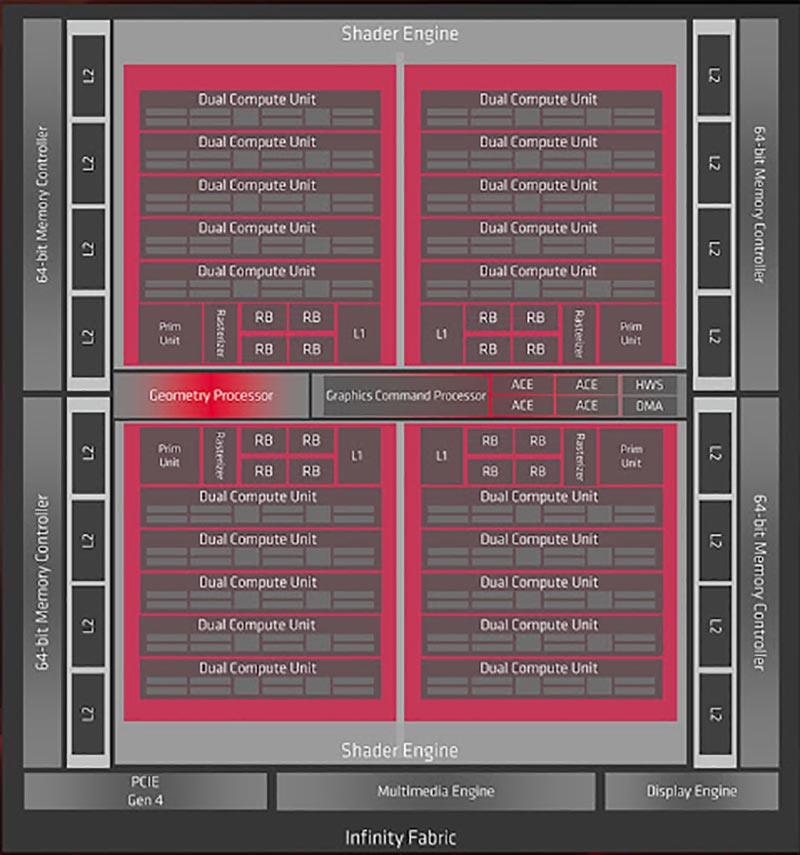
Por otro lado, se aprecia bien la influencia de Raja Koduri en Intel Xe. El ex de la división de gráficos de AMD ha llevado una filosofía similar a Intel con las Execution Units, ya que son duales, y cada dos EUs comparten la misma unidad de control. Es decir, muy similar a lo que vemos en la arquitectura RDNA de AMD como puedes ver en la imagen anterior, donde hablamos de Dual Compute Unit.
En cuanto a NVIDIA, sus CUDA cores son mucho más simples que las EU y CU de Intel y AMD respectivamente, pero incluye más de estas unidades. En el caso de NVIDIA, las CUDA son básicamente unidades de sombreado que son básicamente unidades de enteros y coma flotante de 32-bit:
Como hemos visto en el apartado anterior con las Unidades de Ejecución, que se dedican al procesamiento del sombreado o shader, éstas se dividen en Sub-Slices, que se encuentran agrupadas dentro de las EU de la GPU Intel Xe.
Es decir, tenemos que cada EU es un subconjunto de un subsegmento y el Sub-Slice es el superconjunto del subsegmento. No te preocupes, lo entenderás mejor más adelante…
Lo que Intel denomina subsegmento se compone de 16 EUs en su interior, lo que se traduce en 64 FPUs para FP32 y 64 ALUs para enteros de 32-bit en total. Esto hace que estos subsegmentos sean similares a las Compute Unit de AMD en cuanto a potencia bruta. No obstante, no son exactamente una copia, y la ISA que manejan las GPUs de Intel no será la misma que la de las Radeon…
Dentro del Sub-Slice, o unidad de sombreado básica, se encuentran las partes que habitualmente suelen existir en las GPUs, aunque Intel emplea una nomenclatura diferente a la que usan sus competidores. Por ejemplo, encontramos:
Más información sobre las unidades de GPU aquí.
En Intel Xe, este Media Sampler, como se puede apreciar en las imágenes de la arquitectura de la GPU de Intel, se ha retirado del subsegmento y se ha convertido en una unidad independiente. Esto difiere completamente de los diseños de NVIDIA y AMD.
En las imágenes superiores puedes ver que NVIDIA agrupa muchos de sus núcleos CUDA en un SM, y a su vez varios SM en lo que denomina GPC. Es decir, son Graphics Processing Clusters.
Por otro lado, tenemos que AMD denomina a la agrupación de varias CU como Shader Engine, o motor de sombreado.
Pero Intel en su GPU Xe rompe con esto, y usa el término Slice, que sería el equivalente. En el interior se encuentran los subslices y una serie de unidades de función fija y que también son comunes para NVIDIA y AMD.
Pero la diferencia no solo está nuevamente en la nomenclatura usada por Intel, también hay otro detalle que las diferencia de NVIDIA y AMD. Y es que éstas dos empresas emplean una unidad raster y la que genera el buffer de profundidad unificadas, en la fase raster, con una unidad común. En cambio, Intel ha desacoplado estas unidades y las tiene por separado.
Algo parecido ocurre con el Pixel Dispatch y Pixel Back-End. Estas funciones de las unidades ROP de las arquitecturas de NVIDIA y AMD, en el caso de la GPU de Intel se separan también como dos elementos diferentes. Pero la función es la misma…
Para finalizar, también hay que detenerse en la jerarquía de la memoria caché de la GPU de Intel. Esto también diferencia en gran medida la arquitectura de la GPU Intel de las de NVIDIA y AMD. Como bien sabes, AMD ha introducido su Infinity Cache en la RDNA 2 para las Radeon RX 6000 Series, mientras que NVIDIA sigue también con su propia filosofía en sus GeForce RTX.
En el caso de AMD, como sabrás, se emplean tres niveles de caché, una L0, o de nivel 0, una L1, la y L2. En el caso de NVIDIA tenemos una L1 para cada núcleo y luego una L2 compartida sin más, simplificando la jerarquía para esta memoria, aunque esto no es ni bueno ni malo, simplemente cada uno modifica según le resulte para su arquitectura particular.
En el caso de Intel, la GPU es diferente en este sentido. En el subsegmento de Intel tenemos la la caché de datos L1 y la memoria local compartida. Pero se ha agregado una caché L2 adicional a la que se puede acceder tanto desde un 3D Sampler como desde un Media Sampler. Y esto hace que la L3 sea realmente la caché de nivel superior para esta GPU.
Por otro lado, vemos que suele haber una diferenciación entre la caché L1 para datos para alimentar las EUs y una L2 para texturas. Ahora Intel mantiene una configuración totalmente estándar en comparación con la competencia, algo que no era así en las arquitecturas de GPU presentadas previamente por Intel.
La LLC, en este caso una caché de nivel 3 o L3, también presenta un cambio respecto a anteriores arquitecturas de esta firma. Como sabes, las GPUs actuales soportan una técnica llamada Tiled Caching, que consiste en rasterizar por tiles o partes de la imagen. Esto se hace en el último nivel de la caché, y por eso Intel ha optado por ampliarla de forma significativa, pero es un nivel que no vemos en AMD y NVIDIA…
Con la salida de Raja hacia Tenstorrent, han surgido muchos rumores alrededor de Intel y la continuidad de su división gráfica. De hecho, ya se han cancelado algunos proyectos para HPC, aunque parece que las Intel Arc para el sector del consumo siguen adelante. Sin duda Raja era una persona clave para el avance de Intel en este terreno en el que no contaban con tanta experiencia, pero veremos qué ocurre ahora… ¿Ficharán en Intel a más arquitectos procedentes de AMD o NVIDIA? ¿Abandonarán el proyecto Intel Arc?
Por supuesto, Intel también tiene otras leves diferencias con respecto a AMD y NVIDIA, como puede ser los nodos en los que está fabricado el chip de GPU, el recuento de transistores como es obvio, la PCB, TDP, anchos de bus, etc. Pero a grandes rasgos, son también muchas las semejanzas con sus competidores.
A nivel externo, vemos que las placas de GPU Intel no tienen AIBs como las de NVIDIA y AMD, sino que ellos mismos proveen de una PCB única, de referencia. Por otro lado, en los chips de memoria VRAM integrados en estas tarjetas gráficas dedicadas, no hay demasiadas diferencias con AMD, ya que se emplea la misma GDDR6, igual también que las GPUs dedicadas de NVIDIA en su versión Mobile, ya que las de PC llevan GDDR6X, que es una memoria mejorada desarrollada por NVIDIA y Micron Technologies como sabrás.
Los componentes a nivel de PCB también son similares, además de la GPU y los chips de VRAM, también encontramos otras unidades esenciales como puede ser el BIOS gráfico. Y, como no, los puertos empleados también son estándares, al igual que la interfaz para conectar la tarjeta a la placa base, que también es PCIe.
Seguro que te interesa ver nuestra guía sobre: Mejores tarjetas gráficas del mercado.
Espero que comprendas un poco mejor las diferencias entre las distintas GPUs, y no olvides comentar con tus dudas o sugerencias…
Pioneer ha decidido retirarse del mercado de unidades de disco óptico para PC, poniendo fin…
Manli ha informado que la GeForce RTX 5090D tendrá una reducción de memoria, quedando en…
La RTX Pro 6000 Blackwell ha sido sometida a pruebas, mostrando un rendimiento superior de…