Al igual que en los x86 tenemos extensiones de la ISA como pueden ser AVX-512, MMX, SSE, FMA4, XOP, etc., en otras arquitecturas quizás las extensiones no son tan conocidas, como las Apple AMX, como es en el caso del mundo ARM, concretamente en los Apple Silicon, que emplean esta ISA, pero no demasiados saben qué es lo que realmente utilizan de ese set en las implementaciones o microarquitecturas que usan.
Índice de contenidos

En las máquinas Apple Silicon, como los chips A-Series para dispositivos móviles como en los M-Series para ordenadores, se incluye un repertorio de instrucciones Arm completo, es decir, toda la ISA. Pero también se pueden incluir algunas extensiones adicionales para acelerar ciertas tareas.
Por ejemplo, en los procesadores M1 y M2 existen cuatro formas fundamentales para acelerar algunas aplicaciones:
Quizás también te interese conocer las diferencias entre el Apple M1 vs M2
Hemos citado anteriormente NEON, que es una extensión de instrucciones que se ejecuta en unidades SIMD. Estas unidades se caracterizan por aplicar una sola instrucción sobre múltiples datos, de ahí que las siglas sean Single Insturction Multiple Data. Es decir, son unidades matriciales o de tipo vectorial.
Por ejemplo, cuando un procesador ejecuta una instrucción no vectorial, como puede ser ADD, lo que está haciendo es aplicar esta instrucción que será decodificada en la unidad de control y enviando las señales de control correspondientes a las unidades de ejecución o unidades funcionales de cálculo para ser ejecutada sobre dos datos. Esta instrucción ADD es de suma, por lo que podría sumar dos valores. Por ejemplo:
ADD A, B
↓
A + B = C
Esto sumaría el valor de la memoria A + el valor almacenado en la memoria B. En cambio, cuando se trata de una SIMD, también podríamos tener una instrucción que podría ser VADD, o una suma vectorial. Y en vez de ser aplicada a solo dos datos, sería aplicada a una matriz de datos o un vector de datos. Es decir, a múltiples valores a la vez. Por ejemplo:
ADD Ax, Bx
↓
Ax+ Bx = Cx
↓
A1 + B1 = C1
A2 + B2 = C2
A3 + B3 = C3
A4 + B4 = C4
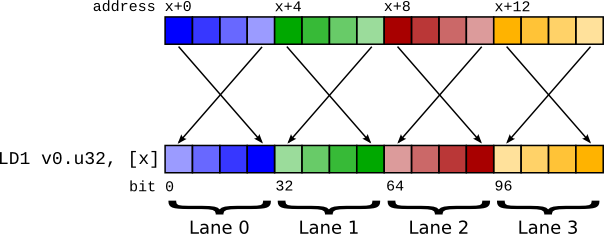
En la arquitectura SIMD, el paralelismo se aprovecha mediante el uso de operaciones simultáneas en grandes conjuntos de datos. Este paradigma es más beneficioso para resolver problemas que tienen varios datos de aplicaciones científicas, multimedia, etc., que necesitan de muchos de estas operaciones sobre múltiples datos.
Como puedes ver en el ejemplo anterior, con una instrucción vectorial se pueden realizar de una sola vez cuatro sumas escalares como las de la instrucción simple. No siempre son cuatro, esto dependerá de la profundidad de las matrices o vectores o de la longitud. Por ejemplo, los procesadores de 64-bit pueden realizar operaciones de palabras de 64-bit. Mientras que si cuentan con extensiones de instrucciones SIMD de 512-bit, podrían estar operando sobre 8 valores de 64-bit a la vez.
Así es como funcionan las extensiones SIMD como las que hoy aquí vamos a presentar…
La arquitectura ARM define la extensión SIMD que se ejecutará en los coprocesadores o FPUs integradas en la microarquitectura de la CPU. Para los procesadores Apple, que usan la ISA ARM, no hay ningún requisito arquitectónico para que un procesador implemente las extensiones NEON.
Cuando se optimiza el código NEON para un procesador en particular, es posible que haya que tener en cuenta aspectos definidos por la implementación de cómo ese procesador integra la tecnología NEON. Esto significa que una secuencia de instrucciones optimizada para un procesador específico podría tener diferentes características de temporización en un procesador diferente, incluso si los tiempos de ciclo de instrucción NEON son idénticos.
Para estas extensiones NEON se aplica el concepto SIMD haciendo que una sola instrucción pueda operar sobre vectores de datos, con longitudes de hasta 128-bit en este caso. La tecnología NEON está implementada en todos los procesadores actuales de la serie Cortex-A de ARM, pero también en implementaciones como las microarquitecturas de Apple.
Las instrucciones NEON se ejecutan como parte del flujo de instrucciones ARM/Thumb. Esto simplifica el desarrollo, la depuración y la integración del software en comparación con el uso de un acelerador externo. Por tanto, también pueden tener acceso a la memoria, copia entre registros de propósito general, conversión de tipos de datos, etc.
Por otro lado, los chips de Apple también hacen uso de las instrucciones Apple AMX. Ten en cuenta que estas instrucciones no están documentadas, por lo que pueden producir una gran confusión. Además, también generan dudas al confundirse con las instrucciones AMX de Intel, pero son totalmente diferentes. No obstante, ambas están destinadas a realizar operaciones de multiplicación matricial desde la FPU de la CPU.
También hay que decir que los procesadores Apple M-Series pueden tener diferentes instrucciones AMX según su generación. Algunas fuentes consideran que el M1 tiene dos versiones diferentes de las instrucciones AMX, usando máscaras de escritura de 7-bit para la primera versión y de 9-bit para la segunda y más nueva versión.
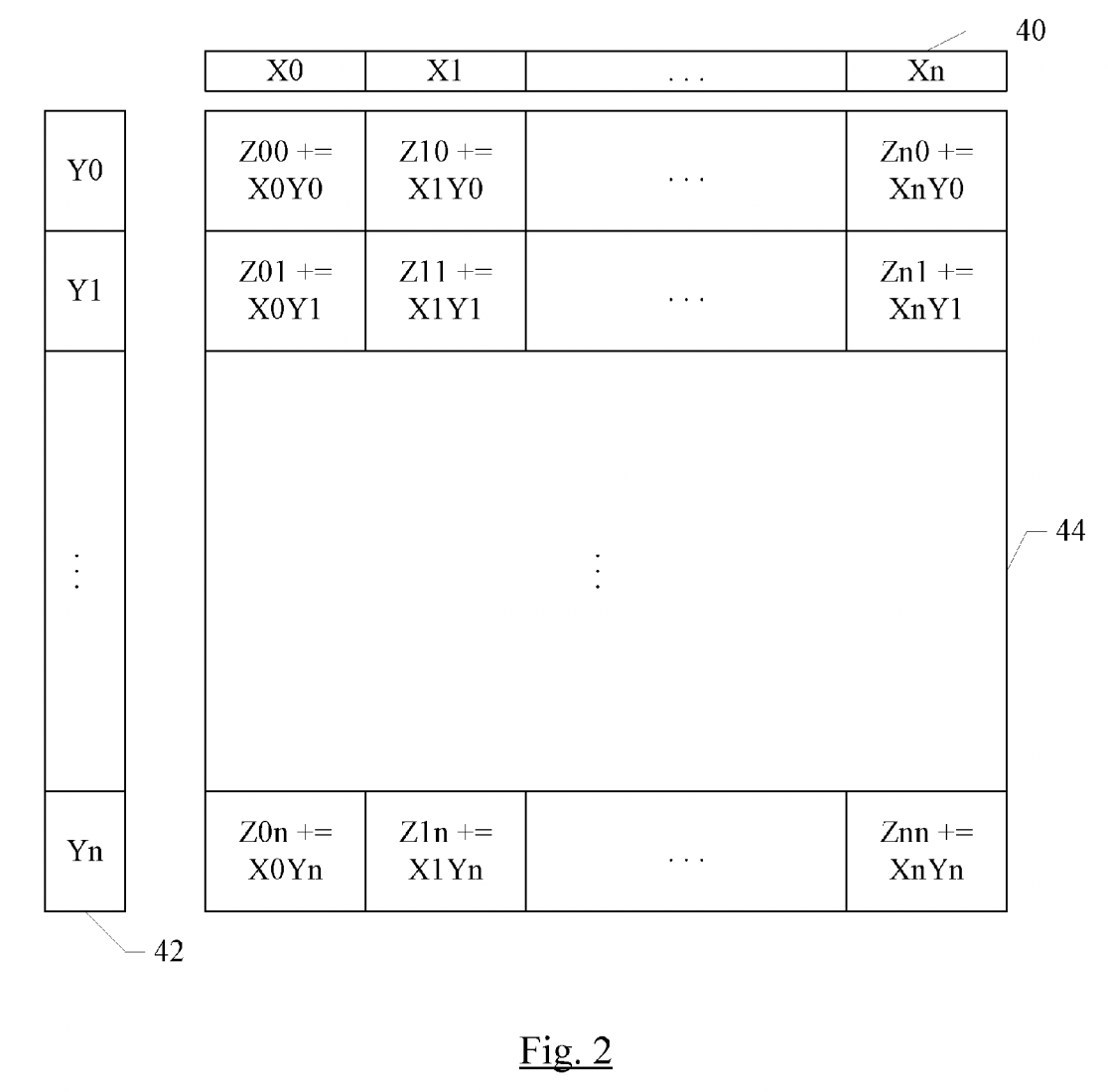
En la siguiente figura puedes ver un ejemplo de instrucciones Apple AMX, donde queda patente cómo funcionan y qué naturaleza tienen. Por ejemplo, imagina una cuadrícula o matriz de datos donde cada unidad puede realizar la multiplicación y acumulación.
Para alimentar esta cuadrícula, hay un grupo de registros X, cada uno de los cuales contiene 32 elementos de 16 bits (o 16 elementos de 32 bits, u 8 elementos de 64 bits) y un grupo de registros Y que contiene de manera similar 32 elementos de 16 bits (o 16 elementos de 32 bits, u 8 elementos de 64 bits).
Una sola instrucción puede realizar un producto externo completo: multiplica cada elemento de un registro X con cada elemento de un registro Y y acumula con el elemento Z en la posición correspondiente para obtener el resultado. De esa forma no se necesita ir procesando instrucción a instrucción escalar aplicada solo a dos valores.
De esta forma funciona esta SIMD de Apple que tan pocos conocen. En definitiva, los tipos de datos que se pueden operar con las extensiones Apple AMX son:
Acer presenta sus nuevos ordenadores portátiles Nitro AI, así como su ordenador de sobremesa Nitro…
En esta guía te voy a explicar cómo editar fotos con ChatGPT. Entre las cosas…
En esta guía te voy a hablar sobre un truco curioso que vas a poder…