Las GeForce RTX 4090 y RTX 4080 (con arquitectura Ada Lovelace) estarán disponibles a partir del 12 de octubre, marcando la llegada de las dos primeras tarjetas gráficas de la arquitectura GeForce RTX 40 Series. Tal y como se predijo, se comenzará por estas dos series, pero luego llegarán otras para los que buscan algo más modesto y barato. Hay una gran necesidad de nuevas tarjetas gráficas como resultado del hackeo de Ampere de Nvidia, que ocurrió a principios de este año.
Ahora Nvidia ha confirmado los detalles de las primeras tarjetas de la serie RTX 40. Todo lo que sabemos y esperamos sobre la arquitectura Ada y la familia de la serie RTX 40 se ha recogido en este artículo.
Índice de contenidos
Ya se conocen algunos detalles, otros aún son simples especulaciones. Pero en esta tabla te puedes hacer una idea aproximada de toda la serie de la arquitectura RTX 40, para hacerte una idea de las futuras tarjetas gráficas:
| GPU / cARACTERÍSTICAS | RTX 4090 | RTX 4080 16GB | RTX 4080 12GB | RTX 4070 | RTX 4060 | RTX 4050 |
|---|---|---|---|---|---|---|
| Arquitectura | AD102 | AD103 | AD104 | AD104? | AD106? | AD107? |
| Nodo | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N |
| Transistores (x1000M) | 76.3 | 45.9 | 35.8 | 35.8 | ¿25? | ¿18? |
| Die size (mm^2) | 608.4 | 378.6 | 294.5 | 294.5 | 225? | ¿175? |
| SMs / CUs / Xe-Cores | 128 | 76 | 60 | 50? | 32? | ¿24? |
| GPU Cores (Shaders) | 16384 | 9728 | 7680 | ¿6400? | ¿4096? | ¿3072? |
| Tensor Cores | 512 | 304 | 240 | ¿200? | ¿128? | ¿96? |
| Ray Tracing «Cores» | 128 | 76 | 60 | ¿50? | ¿32? | ¿24? |
| Boost Clock (MHz) | 2520 | 2505 | 2610 | ¿2600? | ¿2600? | ¿2600? |
| VRAM Speed (Gbps) | 21 | 22.4 | 21 | ¿18? | ¿18? | ¿18? |
| Capacidad VRAM (GB) | 24 | 16 | 12 | ¿12? | ¿8? | ¿8? |
| Ancho de banda VRAM | 384 | 256 | 192 | 192? | ¿128? | ¿64? |
| Memoria L2 Cache | 72 | 64 | 48 | ¿36? | ¿32? | ¿16? |
| ROPs | 176 | 112 | 80 | ¿80? | ¿48? | ¿32? |
| TMUs | 512 | 304 | 240 | ¿200? | ¿128? | ¿96? |
| TFLOPS FP32 (Boost) | 82.6 | 48.7 | 40.1 | ¿33.3? | ¿21.3? | ¿16.0? |
| TFLOPS FP16 (FP8) | 661 (1321) | 390 (780) | 321 (641) | ¿266 (532)? | ¿170 (341)? | ¿128 (256)? |
| Ancho de banda (GBps) | 1008 | 717 | 504 | ¿360? | ¿288? | ¿144? |
| TDP (vatios) | 450 | 320 | 285 | ¿220? | ¿160? | ¿125? |
| Fecha de lanzamiento | Oct 2022 | Nov 2022 | Nov 2022 | ¿Ene 2023? | ¿Abr 2023? | ¿Ago 2023? |
| Precio de salida (aprox.) | 1,599€ | 1,199€ | 899€ | ¿599€? | ¿449€? | ¿299€? |
Se ha comprobado que las tres primeras tarjetas de la lista son exactas, pero las tres últimas aun tienen algunos datos que confirmar. Aunque Nvidia no ha anunciado oficialmente estas GPU, es razonable suponer que saldrán a la venta pronto. También existe una buena posibilidad de que se lancen modelos intermedios aparte de los enumerados aquí. Por ejemplo, Nvidia ha presentado diez variantes de la serie RTX 30, que van desde la 3090 Ti hasta la 3050. Es probable que en el futuro se lancen algunas tarjetas de la serie 40 Ti, ya sea con el sufijo Super o con otra cosa.
Todos los datos de la tabla que están entre signos de interrogación se han calculado según lo que se conoce por el momento y lo visto en las tarjetas gráficas de la serie RTX 30.
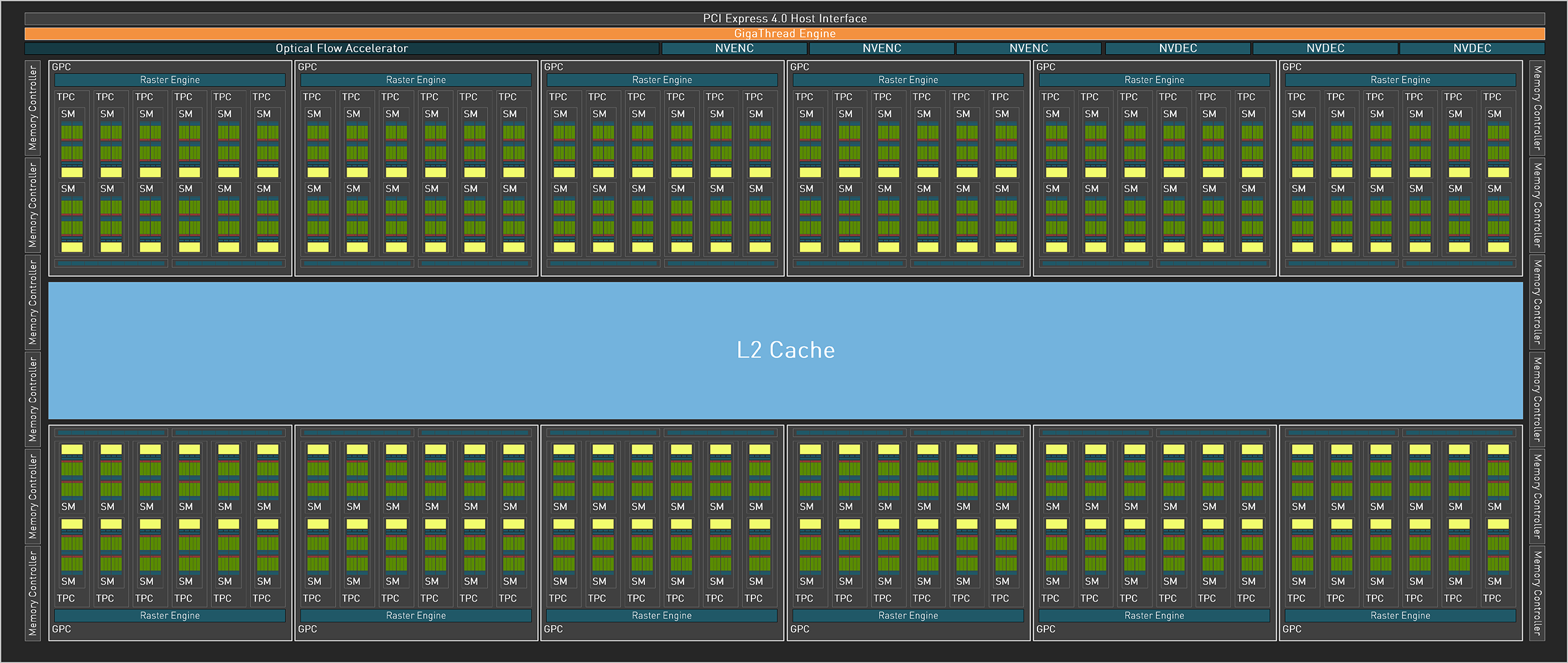
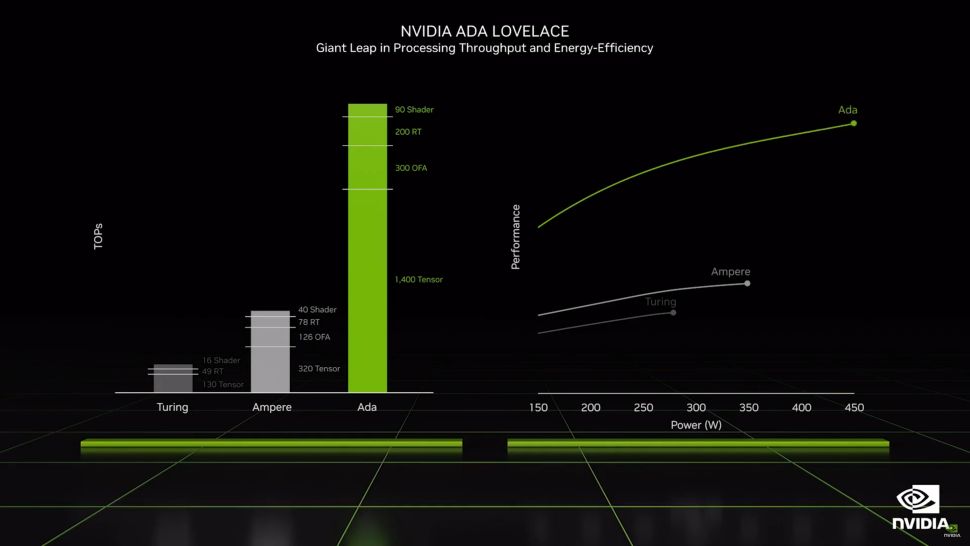
A continuación se explican todos los detalles de las GPU de Ada. En comparación con la generación Ampere, habrá muchos más SM en el chipset AD102. Aunque no haya ningún otro cambio enorme en la arquitectura, la GA102 tendrá un 71% más de SMs que la AD102. En el extremo superior de la gama, esperamos un enorme aumento del rendimiento. La RT 4090 puede realizar cálculos FP16 y FP8 de hasta 661 teraflops, y los núcleos Tensor ahora pueden manejar FP8 (activación dispersa) además de FP16. La RTX 4100 viene con cálculo de aprendizaje profundo/AI de hasta 1.321 teraflops en FP8 y 1,4 petaflops a velocidades de reloj similares.
El GA102 completo de la RTX 3090 Ti ofrece 321 TFLOPS FP16 (cuando se utiliza la técnica dispersa de Nvidia). Según el recuento de núcleos y relojes, la RTX 4090 ofrece un aumento teórico del 107% en el rendimiento. El mismo aumento de rendimiento se producirá también en el hardware de sombreado y trazado de rayos, con la diferencia de que éstos también se actualizarán. Según Nvidia, la función SER en los núcleos de sombreado de la GPU aumentará el rendimiento del trazado de rayos hasta en un 200%, además de aumentar el rendimiento general hasta en un 25%. SER requerirá extensiones propias de Nvidia para funcionar, por lo que los juegos existentes podrían no beneficiarse.
Mientras que el hardware de intersección de rayos y triángulos se ha duplicado en los núcleos RT, los motores OMM y DMM tienen un par de trucos nuevos. La construcción de BVH se ha optimizado con el motor Displaced Micro-Mesh (DMM), que, según Nvidia, permite ahorrar memoria al crear BVHs 10 veces más rápido y con un uso de memoria 20 veces menor (5%). Sin embargo, estas características deben ser utilizadas por los desarrolladores. Se prevé que las GPU Ada Lovelace experimenten un importante salto generacional de rendimiento como resultado de estas modificaciones arquitectónicas. Los desarrolladores deberán habilitar la mayoría de estas funciones, por lo que su uso puede ser relativamente reducido.
Entre las características técnicas más destacadas de esta arquitectura de GPU se encuentran las siguientes:
Algunos de los recuentos de ROP de la RTX 4090 han aumentado drásticamente (por ahora). Sin embargo, Nvidia vincula las ROPs a los Graphics Processing Clusters (GPCs), los clústeres de procesamiento gráfico, pero aún pueden desconectarse. El AD102 tiene 12 GPCs con 12 SMs cada uno, para un máximo de 192 ROPs. La especificación indica 176 ROPs, pero el número real es de 11 GPCs y 192 ROPs. La RTX 4080 está equipada con siete GPCs, al igual que la GA102, aunque hay algunos cambios sorprendentes en los GPCs. Las GPC se dividen en dos clusters en la RTX 4080 de 16 GB, uno de ellos con siete SM y los otros con hasta 12 SM. Sin embargo, los siete están habilitados en la RTX 4080 12GB, que tiene 80 ROPs además de sus 112 ROPs. Una quinta GPC en la RTX 4080 12GB tiene doce SMs, para un total de 80 ROPs.
No tenemos información sobre qué GPUs se utilizarán Ada, y puede que haya otros modelos intercalados (por ejemplo, la RTX 4060 Ti). Sin embargo, podemos hacer una conjetura decente sobre las tres tarjetas restantes. A medida que obtengamos más información en los próximos meses, conoceremos más sobre Ada y sus GPUs a medida que se acerque el lanzamiento de las otras GPUs de Ada.
Según Micron, la memoria GDDR6X que funcionará a 24 Gbps saldrá a la venta en breve. Dado que Nvidia es la única empresa que utiliza GDDR6X en sus productos, es probable que Nvidia Ada utilice GDDR6X a 24 Gbps. La única explicación razonable para esto son las GPUs de nivel inferior, que es más probable que utilicen GDDR estándar en lugar de GDDR6X como resultado. El problema aquí es que las GPU tienden a requerir más computación y ancho de banda para cumplir los objetivos de rendimiento. Por ejemplo, la RTX 3090 Ti tiene un 12% más de computación que la RTX 3090 y la GDDR6X de 18 GB tiene un 8% más de ancho de banda. Parece haber una gran discrepancia entre los resultados de computación proporcionados anteriormente y lo que Nvidia afirma para la RTX 4090. Teniendo en cuenta el ancho de banda estimado de 1008 GB/s de la RTX 4090 Ti, ¿tendrá la RTX 4090 24GB GDDR6 o el doble de computación que la RTX 3090?
La memoria GDDR6X puede ayudar a reducir el consumo de energía en las GPU de nivel inferior si el ancho de banda sigue evolucionando. Las Nvidia RTX 3050 a RTX 3070 utilizan una memoria GDDR6 estándar que funciona a 14-15 Gbps. Las RTX 4090 y 4080, suponiendo que utilicen memoria GDDR6 a 18 Gbps, deberían ser capaces de seguir el ritmo del aumento de la potencia de cálculo de las GPU. Es posible que se utilice GDDR6X en las GPU de nivel inferior si Nvidia necesita más ancho de banda. Dado que conocemos las especificaciones del núcleo de las RTX 4090 y 4080, sólo podemos suponer que Nvidia no necesitará aumentos drásticos en el ancho de banda de la memoria pura. Al igual que en el caso de RDNA2 frente a RDNA1, Nvidia probablemente reelaborará su arquitectura para compensar lo que vimos con RDNA2 de AMD frente a su arquitectura RDNA1.
Las cachés se han utilizado durante décadas para reducir los requisitos de ancho de banda de la memoria. Una caché colocada en un chip provoca más visitas a la caché, lo que hace que la GPU extraiga datos de la memoria GDDR6/GDDR6X con menos frecuencia. Las cachés son especialmente esenciales para el rendimiento de los juegos. Gracias a la caché Infinity de AMD, los procesadores RDNA 2 pudieron hacer más con menos ancho de banda bruto, y la información sobre la caché L2 de Ada sugiere que Nvidia ha adoptado un enfoque similar. En la GPU Navi 21, hay hasta 128 MB de caché L3, con 96 MB en la Navi 22, 32 MB en la Navi 23 y sólo 16 MB en la Navi 24. Incluso la caché más pequeña, de 16 MB, aumenta el rendimiento de la memoria. Nos sorprendió que la Radeon RX 6500 XT fuera tan capaz a pesar de su modesto ancho de banda de memoria. Básicamente está a la altura de tarjetas con el doble de ancho de banda de memoria.
Según una diapositiva filtrada, las nuevas tarjetas RTX tienen hasta 96 MB de caché L2 en la AD102, que tiene una interfaz de memoria de 384 bits. Sin embargo, parece que las tarjetas con una interfaz de memoria de 128 bits tienen 32 MB de caché L2, y las que tienen una interfaz de 384 bits tienen hasta 96 MB (16 MB por controlador de memoria en lugar de los 32 MB habituales por controlador). La caché L2 de la RTX 4090 (serie RTX 4000) es supuestamente menor que la Infinity Cache de AMD (72 MB frente a 96 MB), pero aún no sabemos su rendimiento ni otras características. Aunque es menor que el Infinity Cache de algunas GPUs RDNA 2, parece que mantiene el ritmo. Por mucho que una Infinity Cache de 16MB o 32MB haya ayudado en las GPUs RDNA 2, es probable que una caché L2 ligeramente inferior rinda igual de bien con una caché L3 más lenta.
La RX 6700 XT tiene un 35% más de potencia de cómputo que la generación anterior de RX 5700 XT. A pesar de que el rendimiento en nuestro benchmarking de GPUs fue un 32% mayor a 1440p ultra, el rendimiento fue casi exactamente proporcional a la cantidad de computación (32%). En cambio, la RX 6700 XT tiene una interfaz de 192 bits y 384 GB/s de ancho de banda, lo que supone un 14% menos que los 448 GB/s de la RX 5700 XT. Como resultado, la gran caché de AMD puede haber proporcionado al menos un 50% de aumento en el ancho de banda. Aunque las GPU Ada de Nvidia tengan resultados similares y parezcan capaces de lo mismo, su ancho de banda efectivo debería seguir siendo amplio. Los métodos de compresión de memoria de Nvidia han demostrado su eficacia en el pasado, por lo que sus cachés pueden no ser tan importantes como las de AMD.
Una de las mejoras destacables con las RTX 4090 y 4080 es que el DLSS 3 está disponible… y requiere una tarjeta gráfica de la serie RTX 40. DLSS 1 y DLSS 2 funcionarán en las tarjetas gráficas RTX de la serie 20 y 30, así como en las GPU de Ada, pero DLSS 3 será diferente. Al parecer, requerirá las nuevas actualizaciones de la arquitectura para funcionar correctamente. Aunque el algoritmo de DLSS 3 es en gran medida el mismo que antes, ahora hay un acelerador de flujo óptico (OFA) que parece extraer vectores de movimiento adicionales de las imágenes anteriores. El OFA se utiliza entonces para crear una segunda imagen a partir de una única imagen de origen. Todo esto suena un poco a la deformación espacial asíncrona de los días de la RV, sólo que ahora se utiliza para el aumento de escala. Por supuesto, está mejorado por la IA, pero no es ASW. Desde un alto nivel, hay ciertamente algunas similitudes.
Antes de ver su rendimiento, tenemos que ver su aspecto. Nvidia demostró que DLSS 3 mejoraría el rendimiento en un 73% mostrando una diapositiva de rendimiento de DLSS 2 de 63 fps y otra de DLSS 3 de 101 fps. Al menos, eso es lo que dijeron, ya que se necesita más potencia de cálculo para hacer lo mismo. Será un ajuste extra, para que los usuarios puedan elegir si habilitan o no la generación de fotogramas. Los desarrolladores podrán dar soporte tanto a las tarjetas de la serie RTX 40 como a las anteriores con DLSS 2 siempre que la generación de fotogramas esté desactivada. También se ha promocionado Streamline, la API de Nvidia que permite a los desarrolladores de juegos soportar fácilmente DLSS 2 y DLSS 3, así como Intel XeSS y AMD FSR 2.0.
Nvidia ha revelado que las tarjetas gráficas GeForce RTX 4090 y GeForce RTX 4080 contarán con dos de sus unidades de hardware Nvidia Encoder (NVENC) de octava generación, que también soportarán la codificación AV1. La codificación AV1 mejora la eficiencia en un 40%, según Nvidia, lo que significa que los livestreams que utilicen el códec tendrán un 40% más de tasa de bits que los streams H.264 actuales. Por supuesto, un servicio de streaming debe soportar AV1 para beneficiarse de esto.
Incluso cuando se codifica un solo flujo, los dos codificadores pueden dividir el trabajo, multiplicando el rendimiento de la codificación. Los editores de vídeo se beneficiarán del aumento de rendimiento, y Nvidia está colaborando con DaVinci Resolve, Voukoder y Jianying para dar soporte a la aplicación en octubre. El nuevo hardware también será utilizado por GeForce Experience y ShadowPlay para capturar partidas en hasta ocho K y 60 fps HD. Si lo construyes, ¡el 0,01% que puede ver contenidos nativos en 8K vendrá! Las unidades NVENC siguen ofreciendo H.264, HEVC y otros formatos.
Se dice que los nuevos modelos RTX 4080 y RTX 4090 tienen los mismos TBP de 450W que la RTX 3090 Ti. Según las especificaciones de la Founders Edition, las RTX 4080 y RTX 4090 consumen 320 y 285 W, respectivamente. Los diseñadores de las tarjetas gráficas Ampere siempre han estado dispuestos a utilizar consumos más elevados para obtener más rendimiento. Es probable que las futuras tarjetas gráficas RTX 4090 Ti consuman aún más energía que las actuales. Por tanto, no hay razón para que no se creen tarjetas RTX 4090 personalizadas que consuman hasta 600 W.
Con la llegada del escalado de Dennard, la reducción de las dimensiones de los MOSFET, y la muerte de la Ley de Moore, estamos asistiendo a una reducción del tamaño en todos los frentes. El escalado de Dennard se refiere a una reducción de las dimensiones en un 30% en cada generación. El voltaje se reduce en el mismo porcentaje, y los retardos de los circuitos también disminuyen en un 30%. Además, las frecuencias aumentan un 40% y el consumo de energía disminuye un 50%. Si todo esto parece demasiado bueno para ser verdad, es porque el escalado Dennard llegó a su fin en 2007. Gracias a ello, la Ley de Moore no fracasó del todo; sin embargo, los beneficios se hicieron mucho menos llamativos. El Pentium 4 Extreme Edition, que funcionaba a 3,7 GHz en 2004, es el mismo que cuando el Core i9-12900KS alcanzó los 5,5 GHz en 2019. Aunque la frecuencia ha aumentado casi un 50% a lo largo de seis generaciones (o más, dependiendo de cómo las cuentes), las velocidades de reloj en los circuitos integrados solo han aumentado de 3,7GHz en 2004 a 5,5GHz en 2019.
La densidad de transistores y las frecuencias de los chips actuales pueden mejorarse utilizando un nuevo nodo de proceso, pero los voltajes y las frecuencias deben permanecer equilibrados. Si quiere un chip que sea el doble de rápido, puede que tenga que utilizar casi el doble de energía. Puede que tengas que sacrificar algo de rendimiento para aumentar la eficiencia, o puede que no. Aunque Nvidia no ha rechazado del todo la preocupación por la eficiencia en Ada, parece perseguir más rendimiento. Fíjate en la RTX 4080 de 12 GB como ejemplo. Nvidia ha indicado que su rendimiento se acercará al de la generación anterior RTX 3090 Ti, consumiendo un 37% menos de energía. Incluso puede aumentar el rendimiento mientras consume menos energía cuando se utiliza con DLSS 3 y cargas de trabajo RT pesadas. No obstante, habrá que ver cómo se comportan las tarjetas en una serie de juegos.
El sector de las tarjetas gráficas está dominado por Nvidia desde hace varios años. Gracias a su control del 90% del mercado de tarjetas gráficas profesionales, Nvidia ha podido impulsar el desarrollo y la adopción de nuevas tecnologías como el trazado de rayos y el DLSS. En los últimos años, la importancia de la IA y la computación para la investigación científica y otras tareas computacionales ha aumentado, al igual que la demanda de procesadores similares a los de las GPU, lo que ha impulsado la entrada de otras empresas en el sector, especialmente Intel.
Intel no ha hecho un intento serio de crear una tarjeta gráfica dedicada desde finales de los años 90, aparte del fallido Larrabee. Esta vez, Arc Alchemist parece ser el verdadero negocio, al menos en lo que respecta a las capacidades multimedia. A pesar de lo que sabemos, todavía hay mucho debate sobre el rendimiento de los juegos y la capacidad de cálculo general de Arc. Los modelos de consumo de gama más alta, como mucho, ofrecerán 18 TFLOPS. Consulta nuestra tabla en la parte superior para ver cómo se compara con la RTX 4060, si es que lo hace.
Es posible que la innovación de Arc se amplíe en el futuro, y si es así, puede dar un gran mordisco a la cuota de mercado de Nvidia en los portátiles para juegos. Si Arc no tiene éxito y hay un exceso de GPUs Nvidia de la serie RTX 30, Intel podría ser incapaz de competir.
Si todo va como está previsto, AMD lanzará los chips de la arquitectura RDNA 3 a finales de año, como ha anunciado en varias ocasiones. AMD ha dicho que presentará la futura tecnología el 3 de noviembre. Además, AMD utilizará el nodo N6 de TSMC para los chiplets de memoria, además del nodo N5 para los chiplets de la GPU. A pesar de evitar poner hardware de aprendizaje profundo en sus GPU de consumo (a diferencia de su serie MI200), AMD puede centrarse en las mejoras de rendimiento sin tanto reto de escalado (FSR 2.0 cubre también esta funcionalidad y funciona en todas las GPU).
Tampoco hay duda de que las tarjetas de la serie RTX 3000 de Nvidia ofrecen actualmente un rendimiento de trazado de rayos significativamente mejor que el de AMD, pero esta última se ha mantenido relativamente callada en lo que respecta al hardware de trazado de rayos y a la necesidad de efectos de trazado de rayos en los juegos. Intel, por su parte, parece ofrecer un rendimiento de trazado de rayos decente, al menos hasta el nivel de la RTX 3070 (más o menos). Sin embargo, si la mayoría de los juegos siguen ejecutándose con rapidez y se ven bien sin efectos de trazado de rayos, será difícil convencer a la gente de que actualice sus tarjetas gráficas.
Ahora ya conoces un poco más a fondo esta arquitectura. ¿Serás uno de los primeros compradores?
AMD está confirmando que sus procesadores EPYC Venice "Zen 6" de próxima generación serán los…
Nvidia anuncia la nueva tarjeta gráfica RTX 5060 para aquellos jugadores que quieren el mejor…
Nvidia acaba de anunciar el lanzamiento de la tarjeta gráfica RTX 5060 Ti, que estarán…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}