
Vamos a explicar cómo funcionan estos Streaming Multiprocessor de NVIDIA, los cuales han cobrado protagonismo ante la llegada de las RTX 40. Existen desde hace una década y estableceremos las diferencias con otras piezas de hardware muy similares en GPUs.
Toca hablar de arquitecturas y de la importancia de ciertas piezas hardware para darle coherencia al todo. Ya hemos hablado de los Stream Processors y de los CUDA Cores, pero ahora toca subir de nivel para hablar de los SM que NVIDIA utiliza en sus tarjetas gráficas, ¡vamos allá!
Índice de contenidos
Qué es el Streaming Multiprocessor de NVIDIA

El SM o Streaming Multiprocessor es un procesador con propósito general que tiene una frecuencia baja y un caché pequeño. Su misión es ejecutar varios bloques de hilos en paralelo; en cuanto uno de sus bloques de hilos completa la ejecución, se pasa al siguiente bloque en serie.
Dentro de un SM encontramos:
- CUDA cores: unidades con funciones especiales (SFU), unidades de punto flotante de precisión simple y doble.
- Caché:
-
- De nivel 1, para reducir la latencia cuando se accede a la memoria.
- Memoria compartida usada para compartir datos entre hilos.
- Caché constante, usada para transmitir lecturas desde una memoria de solo lectura.
- Caché de texturas.
-
- Planificadores para warps.
- Muchos registros.
La GPU programa bloques de hilos a un SM, y todos los hilos dentro de un bloque deben residir en solo SM. Cada bloque se divide en fragmentos de 32 subprocesos consecutivos llamados warps.
Digamos que un SM puede tener hasta 8 bloques de hilos en total, por lo que, cada vez que un SM ejecuta un bloque de hilos, se ejecutará todo en ese SM al mismo tiempo. Si necesitamos liberar memoria de un bloque de hilos, es esencial que todo el conjunto de hilos de ese mismo bloque haya terminado la ejecución.
Más abajo, veréis que el Streaming Multiprocessor ha evolucionado conforme han ido sucediéndose las arquitecturas y generaciones de tarjetas gráficas NVIDIA. Igualmente, la idea básica es la siguiente:
- 1 SM contiene 8 núcleos escalares que pueden funcionar simultáneamente.
- Cada núcleo ejecuta un mismo conjunto de instrucciones, o se queda en reposo.
- El SM programa las instrucciones a través de los núcleos.
- Hasta 32 hilos (warps) pueden ser programados al mismo tiempo.
- A nivel de hilos, se comparte memoria a través de Shared Memory.
- La memoria del registro es local para cada hilo y está repartida por todos los bloques de un SM.
Los warps, esenciales para comprenderlo
Hemos dicho que un bloque de hilos se divide en fragmentos de 32 subprocesos llamados warps, y éstas «deformaciones» (es su traducción al español) ejecutan la misma instrucción. Los warps son elegidos en serie por el SM y cada uno ejecuta la misma instrucción en un momento determinado (SIMD).
Dejando al lado los bloques, cada warp tiene un planificador de warp llamado Warp Scheduler. Cada warp permanece en el planificado que se le asigne, aunque el programador puede cambiar entre warps concurrentes.
Un warp se detiene cuando la siguiente instrucción no se puede ejecutar en el ciclo siguiente, así que el planificador deberá cambiar a un warp que sí puede ejecutar la instrucción.
Historia de la evolución de los Streaming Multiprocessors
Normalmente, el hardware se inventa para solucionar un problema, y el problema lo tenía NVIDIA en 2005 con las primeras GeForce GTX, concretamente con las 7900 GTX. Dicho modelo venía potenciada por la GPU G71, cuya estructura se ordenaba en 3 secciones:
- 8 unidades de procesamiento de vértices.
- 24 unidades de generación de fragmentos.
- 16 unidades de fusión de fragmentos.
Digamos que se trata de una estructura de 3 capas, y para explicarlo me voy a apoyar en el gráfico de Fabien Sanglard, quien lo explica a la perfección.
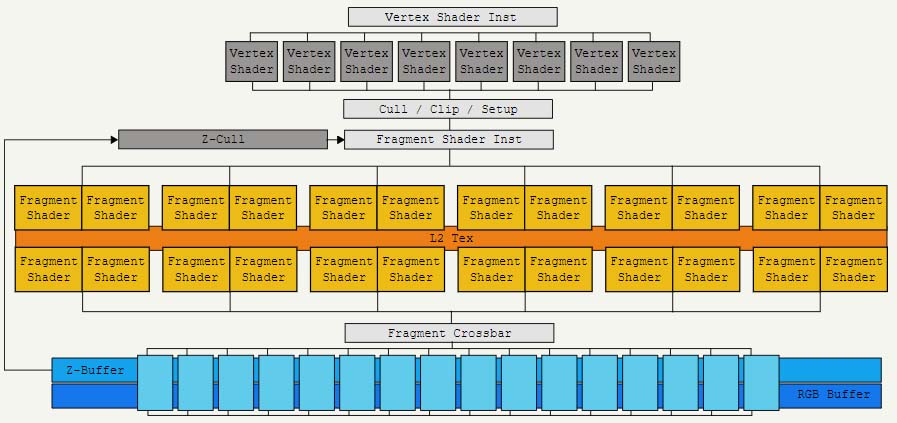
Los diseñadores tenían un problema porque no sabían cómo ubicar el cuello de botella con el fin de equilibrar cada capa. A esto hay que añadirle la salida de DirectX 10 con los sombreadores de geometría, así que había que hacer un cambio de arquitectura importante.
2006, Tesla resuelve el problema
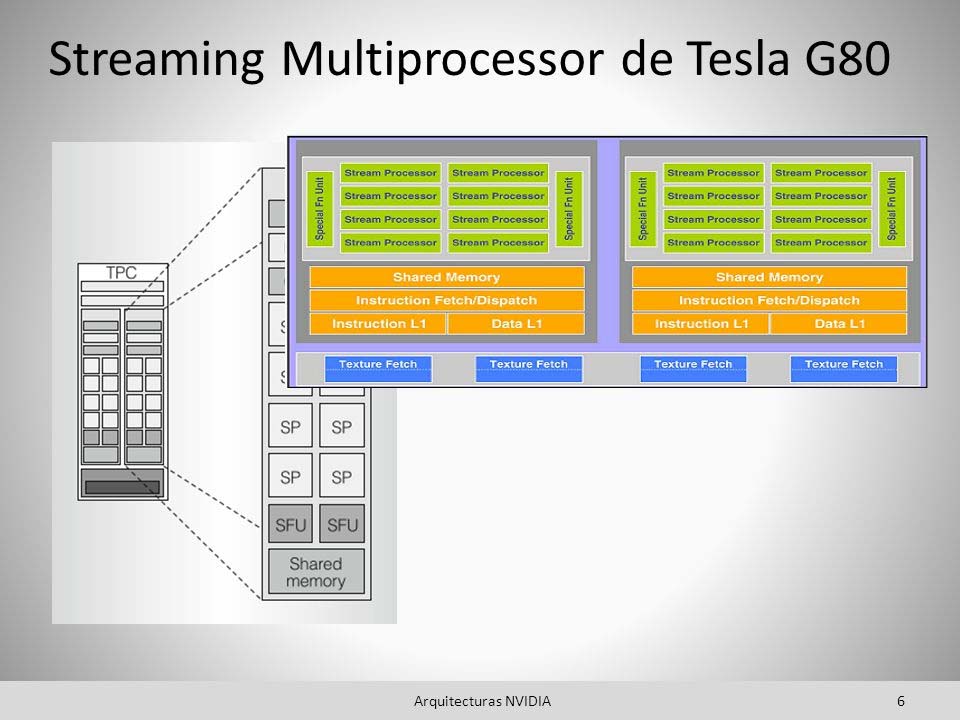
NVIDIA decidió resolver el problema con la arquitectura Tesla, eliminando la distinción entre capas: nace el Streaming Multiprocessor (SM). Éste sustituiría todas las unidades anteriores (procesamiento de vértices, generación de fragmentos y fusión de fragmentos) ejecutando todas ellas sin distinción.
Eso sí, ya no habría compatibilidad con SIMD, sino que las unidades de sombreado serían núcleos con capacidad para una instrucción FP32 por reloj. El SM recibe hilos en grupos de 32 que se llaman warps, y todos éstos ejecutarán la misma instrucción a la vez, solo cambiando los datos.
A raíz de esto, entra en juego la MT (Multi-threaded Instruction Unit) cuya misión es habilitar o deshabilitar hilos en un warp, si es que el IP se une o se divide. De momento, no había soporte de hardware para FP64, sino que se hacía a través de software.
El Streaming Multiprocessor se ve por primera vez en la gama GeForce 8800 GTX a través de la GPU G80, cuyo proceso era de nada más y nada menos 90 nm. Esta GPU llevaba 2 SM agrupados en un clúster de procesador de texturas (TPC), y eso que la GPU tenía 8 TPC: 128 CUDA cores.
NVIDIA remataba esto con el lenguaje de programación Compute Unified Device Architecture (CUDA). De aquí en adelante, las mejoras que vimos en los SM fueron las siguientes:
- Fermi (2010):
-
- Un SM podía programar 2 half-warp a la vez, a través de 2 conjuntos de 16 CUDA Cores.
- Se multiplicaba por 4 la capacidad del SM de Tesla, además de que las Unidades de Textura ahora formaban parte del SM y el TPC desaparecía.
- El SM estaba potenciado por los Polymorph Engines.
-

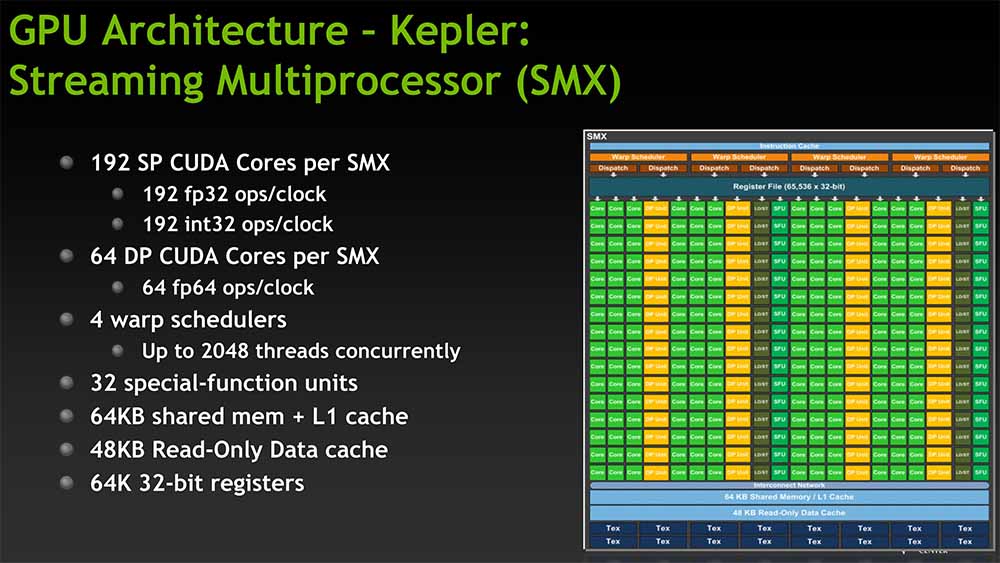
- Kepler (2012):
-
- Entró en juego el SMX, una evolución que triplicaba al SM convencional: tenía 196 núcleos.
- Tenía 4 programadores warp capaces de procesar un arp completo en un reloj.
- Doblaba el rendimiento de Fermi, y solo hay que ver que la GTX 680 venía con 8 SMX y 1536 núcleos.
-
- Maxwell (2014):
-
- Se reducían los CUDA cores frente a la anterior generación: 128 núcleos, pero se ahorraba superficie en el die y energía.
- Pasaron a llamarse SMM, y se podían empaquetar más SMM por die: el doble que Kepler con un aumento del 25% en la superficie.
- La lógica de programación se simplificó para reducir el recálculo redundante y la latencia de cálculo con el fin de mejorar la ubicación de los warp.
- El buque insignia fue la NVIDIA GeForce GTX 980 Ti con una GPU GM200 que llevaba 24 SMM y tenía 3072 núcleos.
-

- Pascal (2016):
-
- A priori, se veía como Maxwell SMM y no había ningún cambio en el diseño de SM.
- Lo que sí se mejoró fue el proceso de fabricación de las GPU: 16 nm, lo que permitió meter más SM y duplicar Gflops.
-

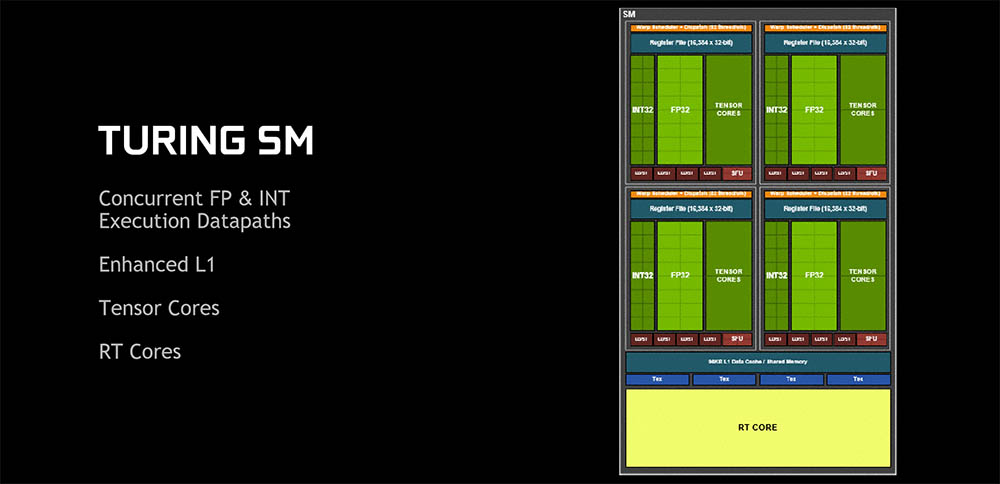
- Turing-Volta (2018):
-
- Rediseño brutal de la arquitectura, con la aparición de los Turing SM, Tensor Cores y RT Cores.
- Si veis el diagrama, veréis que se parece al sistema de capas visto en Tesla.
- En Volta se introdujo una novedad en los hilos y warps: programación de hilos independientes, lo que significa que cada subproceso tiene su IP propia.
- Los SM tienen libertad para programar hilos en un warp sin hacerlos converger.
- Vimos hasta 68 TSM o Turing SM.
-
- Ampere (2020):
-
- Se conservan los 64 warps simultáneos por SM, pero se introducen numerosos cambios en la ocupación del warp, pero destacamos los siguientes:
-
- Se aumenta el tamaño del archivo de registro a 64.000 de 32 bits por SM.
- Ahora el número máximo de registros por hilo es de 255.
-
- Se añade aceleración por hardware para copiar los datos de la memoria global a la compartida.
- Nuevos Tensor Cores que utilizan un tamaño de die más grande y reciben nuevos y potentes modos matemáticos.
- Mejor rendimiento en FP32: el doble en operaciones FP32 por ciclo por SM.
- Se conservan los 64 warps simultáneos por SM, pero se introducen numerosos cambios en la ocupación del warp, pero destacamos los siguientes:
-

Te recomendamos echar un vistazo a la historia de NVIDIA
Stream Processor y Streaming Multiprocessor no es lo mismo

Sabemos que la nomenclatura no ha sido escogida con buena gana porque AMD denomina a sus núcleos Stream Processors. Éstos no equivalen a un Streaming Multiprocessor, sino a los CUDA Cores, que están dentro del SM.
¿Tiene algo similar AMD? Según comentamos en las AMD Radeon RX 7000, las RX 7900 XT tendrán arquitectura MCM y tendrían 2 módulos denominados GCD y MCM. Nos falta información sobre qué hace cada uno en concreto, pero una filtración mostró que dentro de los GCD existen shader engines, que no dejan de ser sombreadores.
Puede que el GCD o el MCM equivalga a un Streaming Processor, pero no nos podemos aventurar a afirmar que así es.
Esperamos que os haya sido de ayuda esta información, y si tenéis alguna duda, podéis comentar abajo para que os respondamos.
Te recomendamos las mejores tarjetas gráficas del mercado
¿Conocíais estos bloques?






