La arquitectura es vital en cualquier GPU o CPU, y es que la MCM estará presente en NVIDIA Hopper, pero ya estaba presente en AMD Zen 2. Activamos el «modo nerd» y nos sumergimos en los entresijos de lo último en hardware.
Consideramos útil conocer la arquitectura Multi-Chip-Module porque está claro que es clave en el empaquetado de procesadores. Los módulos Multi-Chip han estado con nosotros desde los 70-80 a través de IBM, pero este tipo de ensamblaje electrónico no es conocido por todo el mundo. Así que, vamos a intentar explicarlo de la forma más sencilla posible.
Índice de contenidos

La definición corta de la arquitectura MCM sería que se trata de un paquete electrónico compuesto por varios circuitos integrados (2 o más) en un mismo dispositivo. Los componentes de un Multi-Chip-Module se montan en un substrato y los dies de éste se conectan mediante uniones de alambre, de cinta o chip giratorio.
¿Por qué se recurre a MCM? Porque ofrece un mayor rendimiento, reduciendo el tamaño del componente. A través de un sistema MCM, el dispositivo supera las limitaciones de peso y tamaño, además de ofrecer más del 30% de eficiencia. Entre sus ventajas, encontramos las siguientes:
Normalmente, hay 3 tipos de Multi-Chip-Module según su tecnología para crear substratos: MCM laminado (MCM-L), depositado (MCM-D) y cerámico (MCM-C).
Curiosamente, fueron los militares quienes comenzaron adoptando esta tecnología en la década de los 90. El cambio fue brutal porque se utilizaban muchos chips, y no una pieza personalizada. Sin embargo, IBM hizo de las suyas entre los 70 y 80 con esta tecnología; de hecho, han seguido utilizando esta tecnología en sus POWER.
La fabricación de una pieza personalizada eleva los costes de producción de forma abismal, por lo que el sistema Multi-Chip-Module era más interesante. Una de las primeras marcas mainstream en usar la arquitectura MCM fue Intel, allá por 2013 y la llegada de Haswell, procesadores de 22nm por aquel entonces.
«La bestia azul» quiso integrar completamente el PCH (Platform Controller Hub) con la CPU en sus ultrabooks: así nace la plataforma Shark Kaby, un único paquete Multi-Chip Module que integra el PCH de Ivy Bridge con el mismo die del chip Haswell.
Un año después, en 2014, llegaría la arquitectura Broadwell de 14nm, que era una plataforma SoC, un término incorrectamente acuñado por Intel para esta familia de procesadores x86. Lo correcto habría sido decir que utilizaba una arquitectura de sustrato de «apilamiento«, es decir, la famosa MCM: apilar varias matrices verticalmente una encima de otra.
Ya hemos hablado de cómo Intel pensó en esta tecnología MCM para sus Pentium Pro, Pentium D, Xeon y sus Intel Core, pero, ¿qué hacía AMD mientras tanto? Pues bien, en 2010, AMD lanzó sus Opteron 6000, unos procesadores que seguían el diseño Multi-Chip-Module y que estaban conectados en el G35, un tipo de socket LGA.
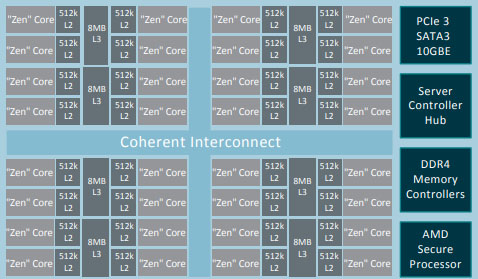
Remarcamos lo de LGA porque AMD siempre ha solido decantarse por un tipo de socket PGA, pero ese es otro tema. El siguiente ejemplo importante de «el diablo rojo» en la arquitectura MCM es con Zen y AMD EPYC, unos chips que son definidos por la propia AMD como «SoC».
AMD recurre a esta arquitectura bajo el argumento de que la escalabilidad en el rendimiento de la CPU, según la Ley Moore, es cada vez más complicada. Así que, toma la decisión de cambiar el diseño de una única matriz a módulos multichip con EPYC en 2017. De hecho, en su explicación de su Multi-Chip Module Architecture afirmaban lo siguiente:
Los procesadores tradicionales colocan 1 o más núcleos de la CPU en un solo die para acelerar la frecuencia y el acceso a la caché. Esto tiene limitaciones: el grosor del óxido, la longitud, el ancho y la densidad del transistor solo pueden ser empujados antes de que las puertas goteen y se genere mucha calor.
Al comprender que los servidores deben seguir el ritmo de las aplicaciones, diseñamos el SoC EPYC utilizando la arquitectura MCM.
Así que, esta arquitectura utiliza varios dies compuestos por varios núcleos y memorias, los cuales están interconectados por AMD Infinity Fabric para reducir la latencia al mínimo y conseguir que la comunicación entre chips sea rápida.
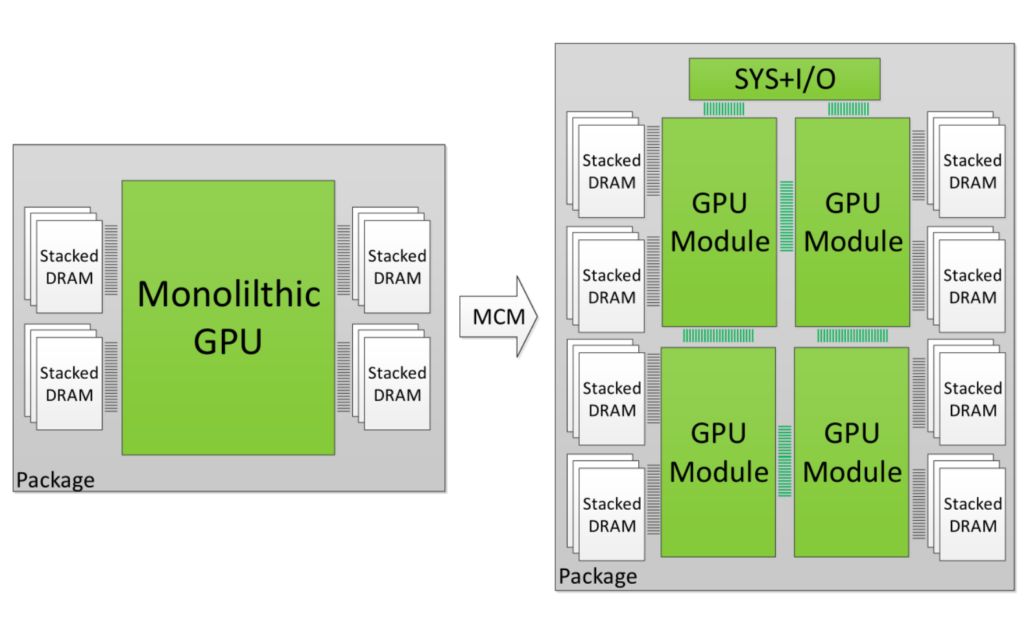
Desde entonces, hemos visto como AMD patentaba una GPU basada en chiplets MCM, dejando entrever que RDNA 3 vendría con este diseño. De este modo, se da paso de una GPU monolítica rodeada de memorias DRAM a una GPU multichip rodeada de los mismos o incluso más chips DRAM.
¿Por qué AMD no optó por este modelo en sus tarjetas gráficas RDNA o RDNA 2? Básicamente, por la alta latencia resultante entre los chiplets. Así que, la compañía debía resolver el problema mejorando la interconexión, algo que podría haber solucionado con «Crosslink«, una interfaz de conexión interna que aporta un ancho de banda más grande.
Todavía es pronto para hablar de RDNA 3 o de CDNA 3, pero seguramente llegue esta arquitectura al sector profesional primero. Tiene pinta de que el equipo de Lisa Su estaría trabajando en llevar esta tecnología a las nuevas gamas de Radeon Instinct.
Respecto a NVIDIA, lleva trabajando en sistemas NUMA y en los módulos multichip desde hace muchos años con la Universidad del Estado de Arizona, la Universidad de Texas y la Universidad politécnica de Catalunya (sí, sorprende lo de ésta última).
Como bien afirma NVIDIA, la mejora de rendimiento en GPUs están relacionada con el escalado de transistores. Llegados a un punto, el número de transistores no crece, por lo que la GPU monolítica no es suficiente para las necesidades de rendimiento en muchos sectores (centros de datos, servidores, etc.).
Así que, en 2017, NVIDIA plantea los módulos de GPU para construir GPUs lógicas más grandes con el objetivo de llevar los límites de la Ley Moore más allá. Lo que ellos proponían era partir la GPU en módulos pequeños que fuesen fáciles de fabricar (llamados GPM). Como hemos dicho anteriormente, estos módulos deben ser integrados con una interconexión.
Por lo que NVIDIA trabajó con estas universidades para estudiar la viabilidad de una MCMGPU a través de 3 arquitecturas posibles. Según las pruebas de NVIDIA, con GPM se logra multiplicar por 5 el ancho de banda, siendo un 45.5% más rápida que una GPU monolítica (que es lo que tenemos hoy en el mercado).
Actualmente, no se sabe mucho sobre las GPUs NVIDIA con arquitectura MCM. Se ha estado barajando que será Hopper, pero luego se ha hablado de Lovelace, así que la compañía todavía está trabajando en ello. Lo que está claro es que la arquitectura Multi-Chip-Module es el futuro porque va a llegar un momento en el que no se va a poder crece más el área de la GPU monolítica.
Por culpa de las necesidades imperiosas de más rendimiento en la computación, el diseño MCM se terminará imponiendo en las próximas generaciones.
Te recomendamos los mejores procesadores y las mejores tarjetas gráficas del mercado
Esperamos que os haya sido de interés este artículo. Si hay algo que no hayáis entendido, podéis comentar abajo y os echaremos un cable en seguida.
Gigabyte está presentando la GPU RTX 5060 OC Low Profile, la más pequeña y compacta…
Las nuevas cifras de ventas sobre la tarjeta gráfica Radeon RX 9070 XT han salido…
Se encuentra nueva evidencia sobre los procesadores Intel Bartlett Lake-S, que podría lanzarse próximamente. Leer…