El fingerprinting es la técnica de tracking y seguimiento de usuarios en páginas web más usada por detrás de las cookies. ¿Sabías que, sin la necesidad de estas últimas, se puede crear una huella digital de tu paso por la red? En este artículo desgranaremos cómo la huella de tu navegador puede “delatarte”, y que conozcas cómo un sitio web puede identificarte sin necesidad de usar ninguna cookie. ¡Comenzamos!

Índice de contenidos
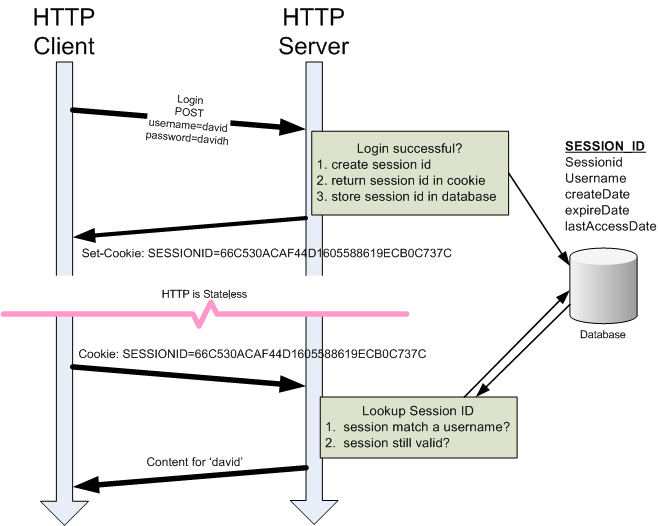
Antes de nada, es necesario que conozcas cuál es el mecanismo básico de funcionamiento de un sitio web que usa cookies.
En tu primera visita a esa web, el servidor de la página le dará a tu navegador un archivo muy pequeño (la cookie) que contendrá un identificador junto con otros datos. Entonces, en las sucesivas visitas que hagas a la web (mientras dure la cookie, que tiene una expiración concreta) el navegador le entregará ese archivo al servidor, que generalmente usará el identificador para acceder a una base de datos con toda la información que hayan guardado.
Este es un mecanismo genial para guardar todo tipo de información de preferencias de un usuario en un sitio web, pero como sabéis también se emplea con fines de seguimiento que a veces se escapan de lo ético. Por eso, desde hace años hay un gran empeño contra las cookies por parte de los gobiernos, y en particular de la Unión Europea, cuyo reglamento de protección de datos (GDPR) obliga a poner el conocido aviso de cookies, que los usuarios pueden rechazar.
De ahí afloran nuevos métodos para hacer seguimiento a las personas por Internet, que son un complemento fácil y poderoso a las cookies.
La base del fingerprinting está en aprovechar todos los metadatos sobre tu dispositivo que dejas al acceder a una página web. Estos los podemos dividir en tres grupos: partes de la cabecera HTTP, información JavaScript, e información de red. Démosles un repaso.
Todo esto sienta el primer precedente para la identificación, aunque evidentemente no son unos datos extremadamente variados.
En este caso os vamos a dar la lista de algunos de los atributos que nos consigue la web AMIUnique de la que os hablaremos a continuación:
Hay todavía más datos, y ciertamente nos permiten dar una imagen bastante clara de identificación del usuario a base de cruzar toda esta información mediante métodos que evidentemente no son sencillos, pero que una empresa con grandes capacidades en cuanto a minería de datos podrá explotar bien.
Aparte de la información localizable por las características de JavaScript del navegador, está claro que también se puede extraer mucha información en relación a la red utilizada para acceder al sitio.
Partiendo de nuestra dirección IP pública, el servidor web puede conocer fácilmente una estimación de nuestra geolocalización, evidentemente todo dependerá de lo bueno que sea el sistema usado y de si nuestra IP es propensa a ser bien geolocalizada o no. Se puede dar el caso de que adivinen la ciudad o incluso el pueblo pequeño en el que vivimos, pero también podemos ver a otros servicios identificándonos en una región totalmente distinta a la que habitamos.
Otras características de la red que son fácilmente detectables incluyen, por ejemplo, el sistema autónomo o ASN utilizado, que tiene que ver básicamente con las direcciones IP que se le tienen asignadas. Aquí lo que conseguirían sería una buena determinación de nuestro proveedor de servicios de Internet, por ejemplo en mi caso una simple comprobación en WhatIsMyASN llegaría a uno de los ASN asignados a Vodafone España.
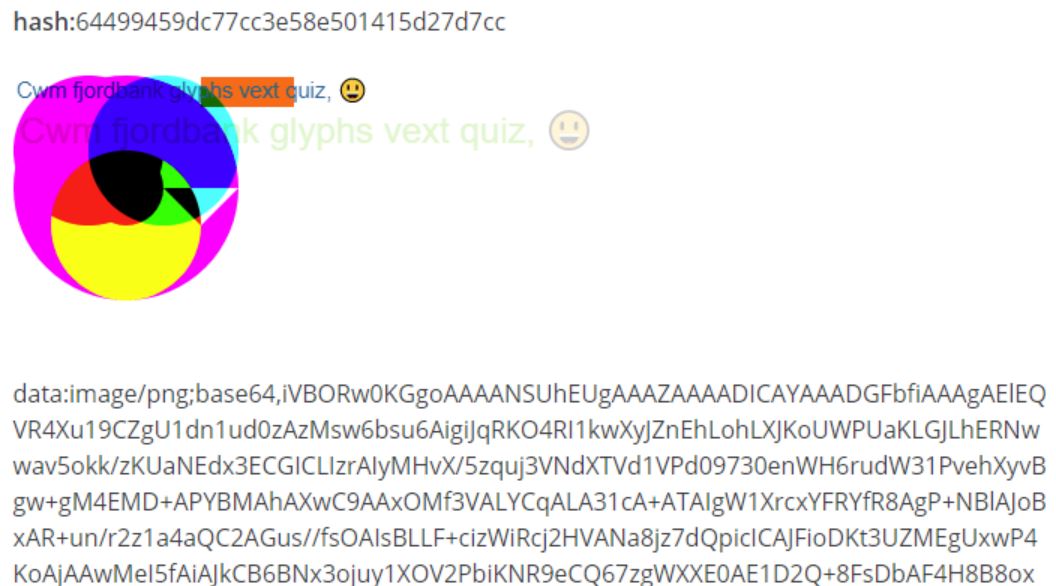
Dentro de este contexto, otra forma de seguimiento muy importante es la huella canvas, también llamada canvas fingerprinting, y que consiste en emplear el elemento canvas de HTML5 en vez de las cookies o los demás datos que os hemos enseñado.
¿Hasta qué punto puede favorecer el seguimiento? En un estudio con unos 300 participantes, se encontró una variabilidad de unos 5 o 6 bits en la huella obtenida en el mismo usuario. Por ello, no es un método que de por sí vaya a dar un gran potencial de identificación, pero es una herramienta más para ejercer un seguimiento relacionado con publicidad.
Una gran pregunta está en hasta qué punto se puede sacar provecho de tanta información, con los fines económicos a los que estamos acostumbrados. Y es que parece que no podemos sacar demasiado de aquí, puesto que se carece de la personalización implícita en las cookies. Pero mediante el uso del big data y minería de datos, y el poder de gigantes como Facebook y Google, se puede crear un perfil anónimo bastante fiel de un usuario y mostrarle publicidad personalizada, o incluso aprovechar inicios de sesión u otras cookies para determinar de manera fehaciente que quien está navegando es una persona concreta.
Una gran empresa con un volumen de tráfico alto y variado, y donde además millones de otras páginas inyectan su código, tiene un buen potencial para hacer fingerprinting.
Una de las páginas webs más interesantes para demostrar la existencia de esta técnica es AMIUnique (“¿soy único?”), donde al entrar se nos registrarán todos los datos antes mencionados, para así determinar hasta qué punto nuestra huella es única en su base de datos.
Para cada dato, nos darán el % de usuarios que comparten esa característica, lo cual nos puede dar una idea muy interesante de qué aspectos nos delatan más. Vamos con un ejemplo, donde me compararé con unas 120.000 huellas distintas recabadas en los últimos 30 días:
Es evidente que la mayoría de usuarios no toma acciones contra estas formas de seguimiento, incluso si conocen todos los métodos usados por las grandes empresas como el fingerprinting. Es una cuestión que cada uno debe valorar. Por ejemplo, personalmente no tomo ninguna acción contra esto, pero seguro que mucha gente ve más riesgos que beneficios. Entonces, ¿cuáles son los métodos más razonables para evitar el fingerprinting? Vamos a enumerar rápidamente algunas ideas:
Se podrían mencionar muchas más técnicas que podrían ayudar a dificultar el seguimiento, pero no estamos lo suficientemente seguros de su utilidad.
En general, es bastante difícil escapar de las garras de los gigantes tecnológicos, pero desde luego no es imposible si nos empeñamos en hacerlo. Todo dependerá de la decisión de cada uno, pues está claro que una buena parte de las personas que conocen estas prácticas deciden rendirse o simplemente ignorar su existencia. Es sin duda una interesante materia de debate que se sale de los propósitos de este artículo, pero para ello también está la caja de comentarios.
La técnica de tracking por excelencia son las cookies, donde un “acuerdo” entre navegador y servidor web, con el beneplácito implícito del usuario, llevan a almacenar un pequeño fichero en nuestro equipo que servirá de identificador en las sucesivas visitas al sitio web. Algo que nos permite guardar preferencias, sesiones u otra información importante, pero también permite que sigan nuestro rastro por la página. En el caso de los gigantes tecnológicos como Facebook o Google, también consiguen seguirnos por miles de sitios web gracias a la integración de sus servicios con ellos, y así nos muestran todo tipo de publicidad personalizada.
Con las cookies en el punto de mira, también afloran técnicas alternativas de trackeo. El fingerprinting es la más importante, y a ella le hemos dedicado este artículo. Se basa en algo tan simple como recabar todos los metadatos posibles que dejamos al acceder a la web, con banalidades como el idioma preferido, navegador usado, preferencias, y decenas de pequeños detalles más. Cuando se combinan todos, consiguen identificarnos de forma única. No sabrán cómo nos llamamos, pero no importa: con técnicas similares a las cookies pueden llegar a saberlo, y en todo caso sí sabrán cientos de preferencias e intereses que podrán usar con fines comerciales.
Es importante saber que esto existe, y a partir de ahí cada uno podrá decidir si tomar acciones al respecto o no. Esta cuestión ya se saldría de los propósitos originales del artículo, que no van más allá de informar, pero desde luego es una materia de debate muy interesante, y como siempre queda abierta la caja de comentarios 😉
MSI MPG 321CURX QD-OLED es el nuevo monitor gaming de gama premium de la marca…
En esta guía te voy a explicar cuáles son los pasos que debes seguir en…
Los controladores Game Ready 576.15 han sido publicados, que vendría a ser un “hotfix” basado…