
La computación con procesador en paralelo lleva con nosotros bastantes años, concretamente desde las primeras implementaciones IBM 704 en 1954. Pero no fue hasta el año 2005 cuando este paradigma de la informática llegó al público de consumo general mediante el procesador multinúcleo, porque esto también es un procesador en paralelo.
Índice de contenidos
Este tipo de procesamiento de tareas es mucho más que simplemente instalar dos procesadores en una misma placa base. En ella entran en juego multitud de reglas y leyes de programación y arquitectura de procesadores que no vamos a poder explicar de forma completa, aunque intentaremos hacer un post lo más útil posible sin aburrir al personal.
Qué es el procesamiento en paralelo

Un procesador en paralelo es el método mediante el cual una serie de tareas e instrucciones se ejecutan de forma simultánea. Como cualquier trabajo en paralelo, se trata de dividir el trabajo en trozos más simples, que actualmente solemos llamar hilos, threads o subprocesos. Cada uno de estos subprocesos es ejecutado en uno de los núcleos del procesador de forma simultánea para aminorar el tiempo de espera entre tarea y tarea. Más adelante lo explicaremos con más detalle.
Sin darnos cuenta (o igual si), tenemos en nuestra casa procesadores en paralelo casi para cualquier tarea, por ejemplo, nuestros móviles cuentan con procesadores multinúcleo capaces de ejecutar varias tareas, nuestros ordenadores también e incluso los televisores inteligentes ya cuentan con procesadores de este tipo.

A nivel industrial y de alto rendimiento tenemos no solo procesadores multinúcleo, sino clusters de ordenadores o multi-procesadores. Estos son capaces de ejecutar tareas de gran volumen conectados a través de la red, y son los llamados superordenadores o supercomputadoras de las que tanto escuchamos oír por su eso en los centros de datos mundiales y para la investigación.
Ley de Moore, y el fin del escalado por frecuencia
El procesamiento en paralelo no se trata simplemente de añadir núcleos a la CPU o de conectar y sincronizar procesadores de distintos nodos. Se requiere una programación mucho más compleja, con capacidad de división y de integración en equipos con procesadores de distintos núcleos.

Debido a esta complejidad en la implementación, los procesadores de consumo general antes de 2005 se basaban en el aumento de frecuencia sobre un solo núcleo. En cada núcleo solo se puede ejecutar una tarea a la vez, y además un instante después de haber terminado la tarea anterior, y a esto le llamamos tiempo de ejecución. Esta variable es el resultado de multiplicar el número de instrucciones por el tiempo de ejecución promedio, y el único factor que influiría sería el aumento de frecuencia.
¿Qué problema tiene aumentar más y más la frecuencia? Pues que es un elemento directamente proporcional al consumo, y a su vez esto influye en la temperatura generada. La fórmula concreta sería esta:
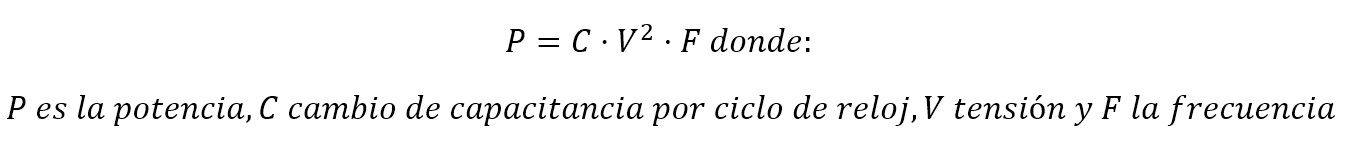
Si aumentamos la frecuencia se aumenta el consumo y el calor, entonces la solución sería obviamente disminuir el voltaje que además influye doblemente en la potencia. Como todos sabéis el voltaje se disminuye haciendo transistores más pequeños que puedan hacer lo mismo con menos energía de paso. Aquí finalmente entra en juego la ley de Moore, un señor que demostró que la densidad de transistores se duplica cada 18 o 24 meses en los procesadores debido a la disminución del proceso de fabricación. Esto efectivamente ha sido así, al menos en AMD, ya que Intel lleva bastante tiempo atascado en los 14 nm.
En 2004 los procesadores de un solo núcleo tocaron techo a unos 4,8 GHz de forma estable y es cuando el paradigma cambió por completo. AMD fue el primero en lanzar su Athlon x2 para consumo general, y posteriormente Intel haría lo propio con el Pentium-D. La ley de Moore sigue teniendo vigencia, pero ahora la cantidad extra de transistores se destinan, no al aumento de frecuencia, sino a aumentar núcleos e implementar nuevas funciones. De esta forma es como hemos llegado a tener un procesador en paralelo dentro de un mismo silicio.
Ley de Amdahl: más es mejor, siempre que la programación sea óptima
Una ley fundamental que se aplica al procesador en paralelo es la Ley de Amdahl. Esta sostiene que la mejora de velocidad en la ejecución de un programa debido a la paralelización de sus procesos estará limitada por el porcentaje de programa que no se pueda paralelizar. Esto nos viene a decir que, si un cierto porcentaje del programa en ejecución funciona solamente con tareas en serie, por el ejemplo un 50%, la aceleración máxima sería de 2x y no importa cuántos núcleos añadamos, habrá una cierta cantidad en la que ya no obtengamos beneficio.
La gráfica que muestra esta ley será la siguiente:

Así que mientras más paralelizado esté el programa, más veloz y más susceptible de añadirle núcleos para aumentar su rendimiento será. Está, junto a otra Ley complementaria de Gustafson afirman que el tiempo de funcionamiento de la parte secuencial del programa (la no paralela) es independiente de la cantidad de procesadores. De esto debemos tener claro que, para sacarle partido a un procesador en paralelo, el programa deber también ser lo más paralelizado posible.
Obviamente entran más variables en juego, pero creemos que no merece la pena complicarle tanto la vida al lector si lo que se pretende es tener una idea más o menos general.
Niveles de procesamiento en paralelo
Ya hemos mencionado que en nuestro ordenador mismamente tenemos un procesador en paralelo, de hecho, tenemos varios más, como son la GPU o el chipset aunque se dedican a otras tareas como los gráficos en el primer caos o periféricos en otro. Existen básicamente cuatro niveles de procesador en paralelo:
Paralelización por bit

La paralelización a nivel más bajo es la que se realiza en las cadenas de bits. Toda instrucción está formada por palabras, que en definitiva son estas cadenas de bits que transportan la información. El contar con palabras más largas, permite añadir más contenido a la instrucción, y en consecuencia hacer más trabajo de una sola vez. En la actualidad todos los procesadores trabajan con palabras de 64 bits, mientras que antes permitían solo 32 bits.
Esto también hace que la programación de aplicaciones haya evolucionado mucho, ya que actualmente se compila siempre en 64 bits siendo programas mucho más rápidos computacionalmente hablando.
Paralelización por instrucción

El siguiente nivel de procesador en paralelo radica en paralelizar instrucciones. En instrucciones sin dependencias entre ellas se puede decir eso de “el orden de los factores no altera el producto”. Las instrucciones se combinan en grupos para ser procesadas de forma paralela en distintas etapas o “pipeline”.
El pipeline es la capacidad del procesador de trabajar con barias instrucciones a la vez, cada una de ellas situadas en una etapa distinta. Cuanto nos referimos a etapas son las típicas de la arquitectura RISC: pedir instrucción -> decodificar -> ejecutar -> acceso a memoria -> escritura que estudiamos en asignaturas de computación o informática.

Los procesadores actuales Intel Core suelen tener unos 14 pipeline, mientras que los Ryzen de AMD tienen 19. Además, son procesadores todos ellos superescalares, es decir, son capaces de ejecutar más de una instrucción a la vez gracias a sus núcleos y sus hilos de procesamiento.
Paralelismo de datos
En este nivel lo que se pretende dividir es la entrada de datos de un programa, que trasladado a nivel de procesador consistiría en asignar un subconjunto de datos a cada procesador o núcleo para que ejecuten la misma secuencia de operaciones. Un ejemplo claro de esto es el trabajo con vectores y matrices, algo muy utilizado en los procesadores gráficos en donde en aplican operaciones similares en grandes conjuntos.
Paralelismo de tareas
Es el caso contrario a lo anterior, ya que en este método, un programa es capaz de entregar tareas al procesador que son totalmente distintas unas de otras para que se realicen en paralelo. Este sería un verdadero programa paralelizado.
Tipos de procesador en paralelo
Ahora es turno de ver lo más importante, ¿qué formas hay de ejecutar tareas en paralelo? Y ya hemos visto la más cercana y clara a nosotros: los procesadores multinúcleo, pero hay algunas más.
Procesadores multinúcleo

Esta es la tendencia actual desde hace más de 10 años ya, concretamente desde sus inicios en 2004 como hemos comentado antes. En un procesador multinúcleo tenemos más de una unidad de ejecución, lo que llamamos núcleos o cores. De esta forma un procesador con varios núcleos puede ejecutar tantas instrucciones de forma paralela como núcleos tenga, y además de forma secuencial y de distinta naturaleza entre ellas.
Pero además de esto, se une la condición de procesador superescalar antes vista, en donde cada núcleo puede ejecutar más de una tarea en un solo ciclo de reloj. Esto se hace creando subprocesos, hilos o threads, que es un flujo de instrucciones más simple que optimiza y disminuye los tiempos de espera de cada núcleo. La esta tecnología se le denomina Multithreading, y se aplica en forma de HyperThreading en Intel y SMT en AMD, creando así procesadores con dos hilos o procesadores virtuales por cada núcleo físicos.
Multiprocesadores simétricos (SMP)

Este es el segundo caso que por lógica nos vendría a la mente si nos imaginamos dos procesadores en paralelo. Efectivamente se trata de tener una placa o PCB en donde dos o más procesadores idénticos entre ellos trabajan con recursos compartidos como será una memoria principal y un bus de datos. A esto también se le llama UMA (Uniform Memory Access).
Lo bueno en este método es su escalaridad la encontrarnos con placas que soportan hasta 32 procesadores, y al hecho de tenerlo todo ubicado en un solo sistema físico. Por el contrario, presenta una clara desventaja como es tener que compartir bus de datos, el cual debe ser controlado y arbitrado para que esté disponible para la CPU que solicite acceso, generando tiempos de espera en las otras unidades.

Este método tiene una variante llamada NUMA (Non-Uniform Memory Access) en donde las CPU no necesariamente serán idénticas, y además cada una de ellas contará con su propia porción de memoria. También se permite el acceso a memoria compartida en donde se ubique procesos relacionados.
Procesadores en clúster

Y este es el caso que más uso tiene en el sector de supercomputación, ya que los superordenadores más potentes del mundo trabajan con este método de procesamiento en paralelo y con el siguiente en la lista.
Consiste en una agrupación de ordenadores a priori independientes que trabajan en colaboración. Esto se realiza gracias a un enlace entre ellos que normalmente será mediante una red LAN de alta velocidad, el llamado clúster Beowulf. Aquí lo ideal es que todos los ordenadores sean idénticos para el que flujo de trabajo sea balanceado, aunque cabe la posibilidad de que sean de naturaleza distinta.
Cuando hablamos de superordenadores que tienen miles de procesadores y decenas de terabytes de memoria RAM, casi siempre son clústeres de este tipo.
MPP o Procesamiento Paralelo Masivo

Los que no forman parte de la descripción anterior seguramente estén metidos en este otro grupo. Un MPP será un solo equipo con multitud de procesadores interconectados en red. En este caso la interconexión es más especializada que en un clúster y no de consumo general, contando cada procesador con su propia memoria RAM y una copia del sistema operativo y aplicación para la ejecución en paralelo.
Procesamiento en paralelo distribuido

Este método está muy de moda en la actualidad, y redes como TOR se basan en este principio para su operatividad.
Aquí lo que se trata es de realizar una computación en paralelo, pero con ordenadores que se comunican a través de Internet, de forma remota y de distinta naturaleza y prestaciones. De esta forma se une la capacidad individual de cada equipo para ayudar a las tareas comunes de la red como es la búsqueda de resultados. Para ello es necesario que cada equipo cuente con la aplicación que se encarga de interconectar los equipos.
El gran problema de este método es que la red de Internet cuenta con mucha latencia para el intercambio de datos, y además no todos los nodos cuentan con el mismo ancho de banda.
GPGPU

El GPGPU o Computo de propósito general con unidades de procesamiento gráfico es otra de las tendencias actuales que se están implementando sobre todo por la gran potencia de cálculo que tienen estos chips.
A diferencia de una CPU, una tarjeta gráfica está construida para trabajar principalmente con operaciones de coma flotante, vectores y matrices en donde la paralelización de procesos es muy alta. Una de estas aplicaciones es precisamente la del procesamiento y renderizado de gráficos 3D en movimiento, que a una CPU le costaría horrores por tener “pocos núcleos”.
La computación por tarjetas gráficas en paralelo es un método ideal de realizar simulaciones y cálculos científicos muy complejos, por ejemplo, resolver problemas matemáticos, trabajos en bases de datos, sintetizar elementos, modelar el comportamiento de fluidos e incluso buscar una vacuna para el Covid-19. Pero también son utilizadas para nuestro beneficio, por ejemplo, en plataformas de juegos a través de la red como es GeForce NOW de Nvidia o Google Stadia.
Conclusiones sobre el procesador en paralelo
Como hemos visto, el procesamiento en paralelo es una de las implementaciones que más beneficios han traído en la era actual, creándose verdaderos monstruos del procesamiento de información a nivel mundial. El llamado TOP500, los ordenadores más potentes del mundo, el procesamiento en paralelo.
Pero también la mayoría de servidores de red actuales cuenta con varios procesadores en paralelo, virtualizados o simplemente CPU con varios núcleos en su interior. Nosotros mismos somos los mayores beneficiarios del procesador en paralelo gracias a los Intel Core, AMD Ryzen de PC, o los procesadores de nuestros teléfonos móviles.
Te dejamos más artículos interesantes sobre hardware para ampliar conocimientos:
Con el incremento del ancho de banda en la red de Internet también se están llegando a cabo implementaciones de procesamiento en paralelo con nuestros propios equipos para así darle uso a los medios ya existentes, lo que también podría ser una extensión del Internet de las Cosas o IoT.






