Desde hace unos años, cuando AMD sacó su apuesta y eslogan «Future is Fusion«, nos hemos ido topando con el fruto de su proyecto, las Apus, desde su primera generación «Llano», a las actuales y más famosas «Trinity» y «Richland» como resultado de la unificación de un procesador y una gráfica integrada dentro de un mismo encapsulado.
Desde principios del 2012, cuando sonó por primera vez el nombre de Kaveri, AMD anunció la cuarta generación de procesadores APU, la que realmente sería la unificación de CPU y GPU, la primera que compartiría más que un simple espacio. Nosotros en ésta primera parte del pre-análisis os daremos a conocer los secretos de su nueva arquitectura y el por qué AMD vio en la fusión de las arquitecturas el futuro del mundo del hardware y el auténtico fruto tras la compra de ATI hace ya muchos años.
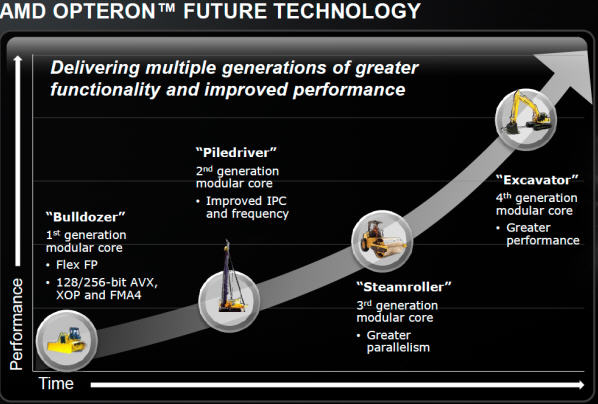
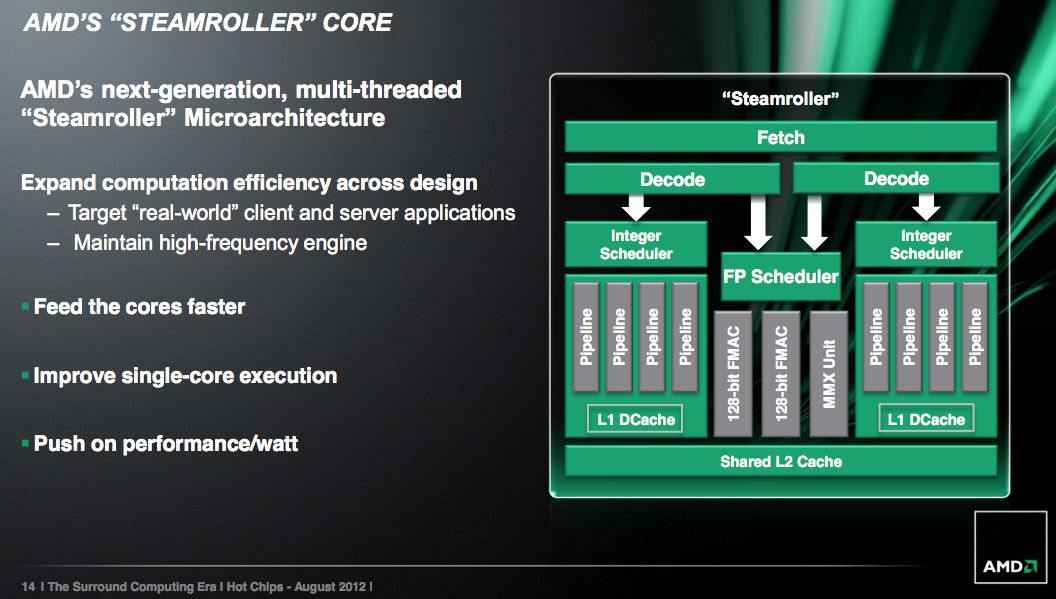
Anunciada en agosto de 2012, éste es uno de los secretos mejor guardados de AMD en cuanto a resultados y pruebas, y es que ésta es la evolución de los vigentes Piledriver, que a su vez fue la evolución sobre Bulldozer. Pero esta vez, es más que una simple evolución ya que cuenta con una serie de cambios profundos que casi lo convierte en una nueva arquitectura y lo dotarán de un gran paralelismo. Conozcámosla.
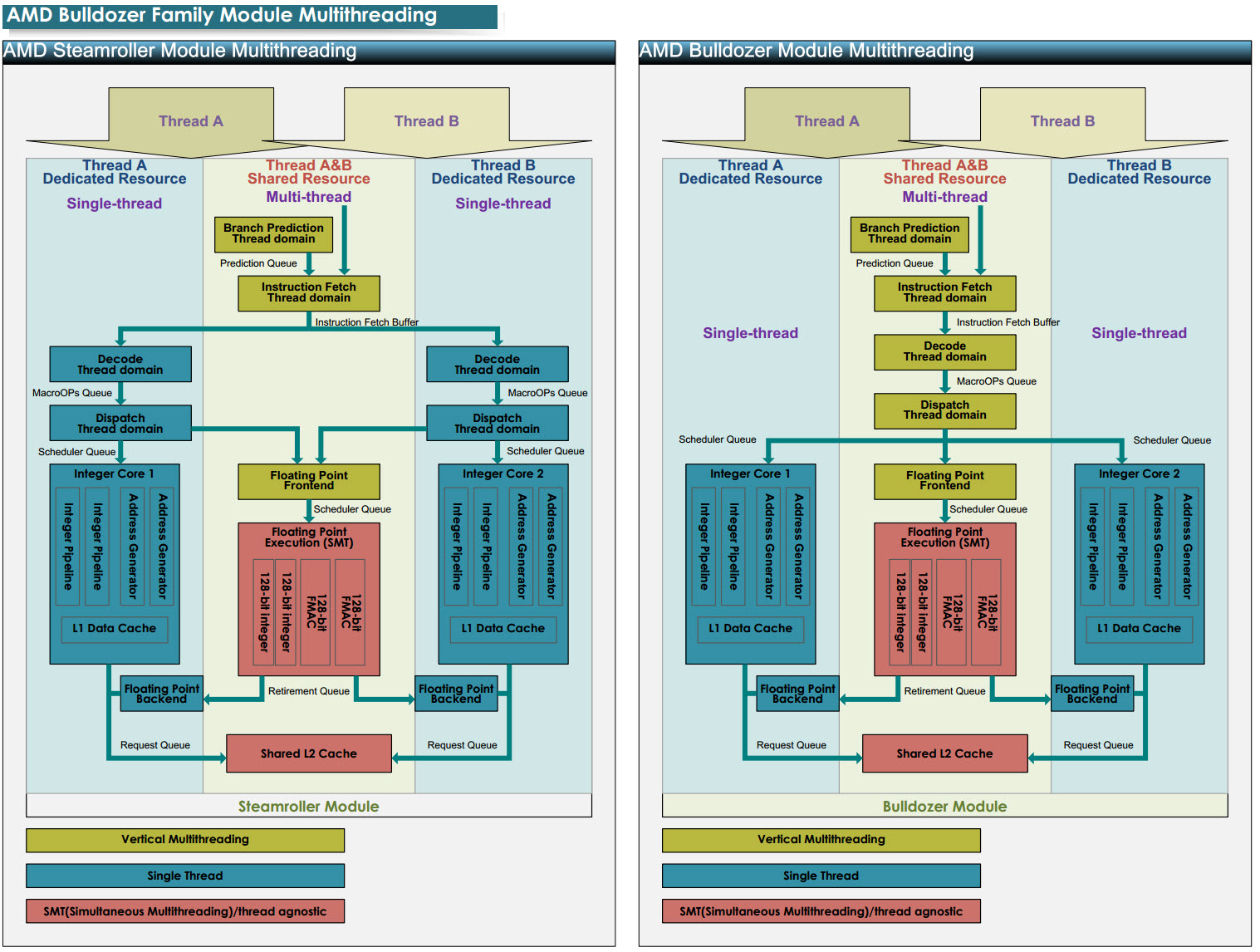
Actualmente todos los procesadores de AMD están basados en arquitectura modular, y cada módulo está compuesto de un decodificador de instrucciones de 4 vías que corresponden a 2 por ALU, dos unidades de enteros (Alus) y una unidad de punto flotante denominada Flex-FP y que comparten buena parte de los recursos para ejecutar hasta dos hilos.
Bien, partiendo de ésta base, en Steamroller se han efectuado cambios profundos para eliminar buena parte de esos cuellos que actualmente se padecen al compartir tantos recursos, y éste rediseño ha dejado sólo la unidad Flex-FP como compartida, mientras que las Alus ahora disponen cada una de su decodificador de instrucciones de 4 vías de forma independiente.
La unidad prefetch también ha sido rediseñada para ser más efectiva y la cache de L1 gozará de menor latencia y será más eficiente que en los actuales Piledriver.
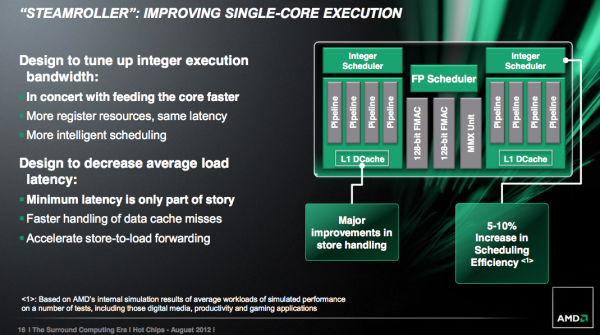
Con éstos cambios el rendimiento aumentará considerablemente al no tener que compartir tantos recursos, motivo por el cual el rendimiento en multi-hilo no es como debiera y ahora, al disponer cada una de las Alus de su propio decodificador y dispatch sin compartirlos, el rendimiento por ciclo aumentará hasta un 30%.
Steamroller hereda la unidad de predicción de Piledriver pero, pero mejorada para ofrecer un rendimiento más consistente sobre todo en cargas de trabajo de servidor.
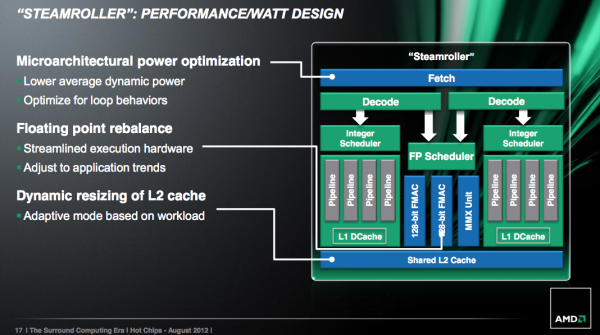
AMD ha optimizado la gran y compartida unidad de punto flotante en cada módulo de Steamroller, aunque no hay cambios en las capacidades de ejecución de la FPU, pero si tenemos una reducción de su área total. Ahora, la unidad MMX comparte parte del hardware con los pipes FMAC de 128-Bit. AMD no ha dado demasiados detalles al respecto, sólo para decir que el hardware compartido en realidad sólo se aplica para las operaciones de MMX / FMA / FP mutuamente excluyentes y por lo tanto no se traduciría en una pérdida del rendimiento.
La reducción de los recursos de los pipes se supone que ofrecen el mismo rendimiento con menor consumo y área de espacio, es decir, una aplicación más inteligente de la FPU de Bulldozer y Piledriver.
Los archivos de registro de enteros y de punto flotante son más grandes en Steamroller, aunque AMD no ha especificado hasta que punto han crecido. Las operaciones de carga (dos operandos) también se comprimen para que sólo tienen una única entrada en el archivo de registro físico, que ayuda a aumentar el tamaño efectivo de cada uno de RF.
La programación de las ventanas también aumentó de tamaño, lo que permitirá una mayor utilización de los recursos de ejecución vigentes.
La cache L1, que si bien es compartida, también aumentará de tamaño en Steamroller, aunque AMD aun no ha mencionado en que cantidad. Bulldozer posee 64Ks de cache L1 de 2 vías, y cada núcleo de dentro del módulo emplea una de las vías. Éste enfoque le dio a Bulldozer menos cache por núcleo que diseños previos, por lo que mejorar ésta parte tiene mucho sentido. Afirman que una cache L1 de mayor tamaño puede reducir la tasa de «fallos» hasta un 30% en la i-cache, aunque no mencionan si han aumentado o no la d-cache.
El interfaz de la cache L1 y L2 ha sido mejorado. Algunas colas han sido mejoradas como también su lógica.
Otra de las novedades a mencionar son las librerías de alta densidad, fruto de la compra de ATI y que son empleadas en el mercado GPU.
Éste método de trabajo proviene del diseño de los núcleos gráficos y ya vimos los primeros resultados en Bobcat. Como ejemplo, AMD demostró hasta una reducción en un 30% del área de espacio y en consumo cuando fue aplicada a la FPU de Bulldozer fabricada en 32Nm.
Para comprender mejor éstos cambios, os dejamos un reciente esquema que compara la arquitectura inicial Bulldozer con la futura Steamroller.
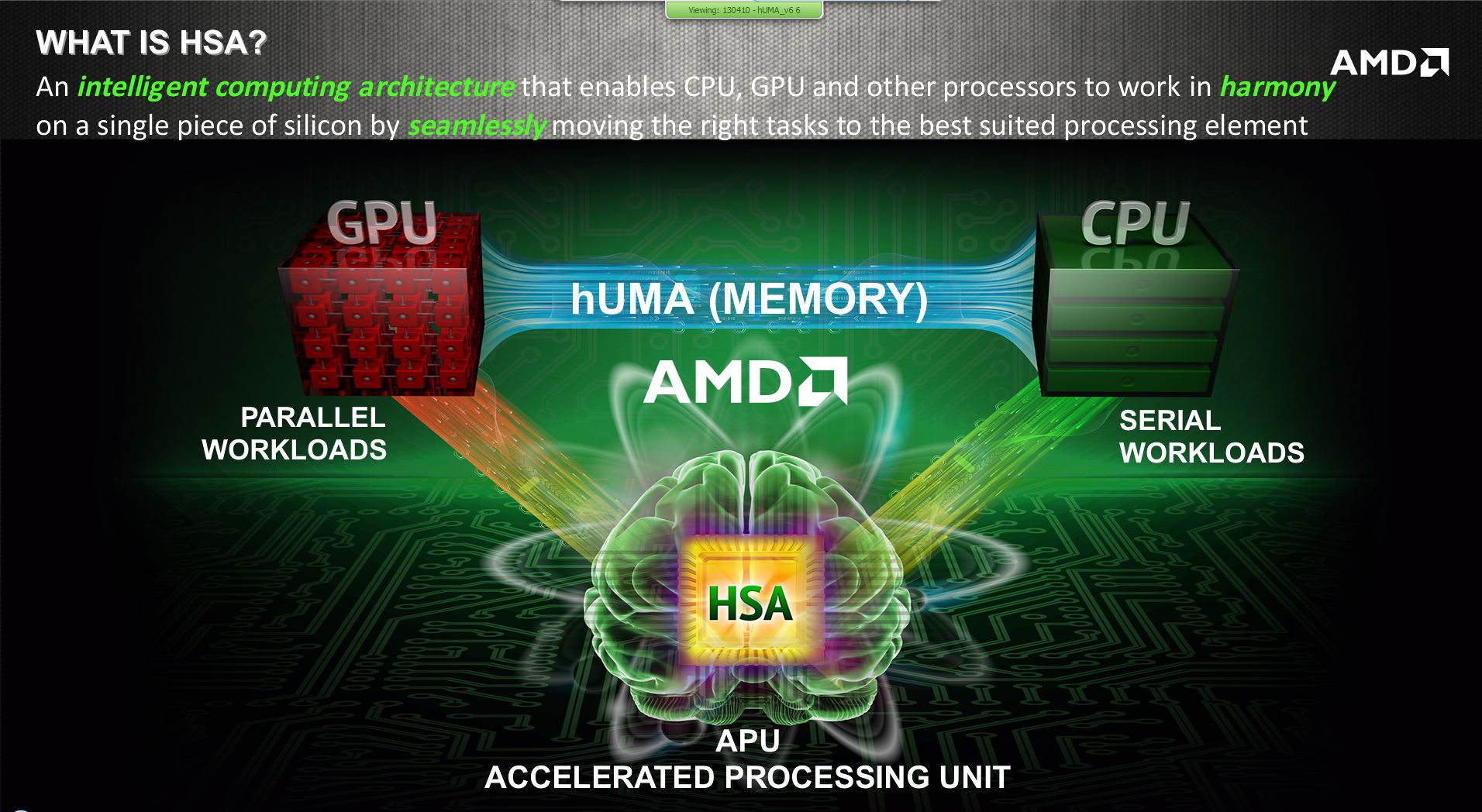
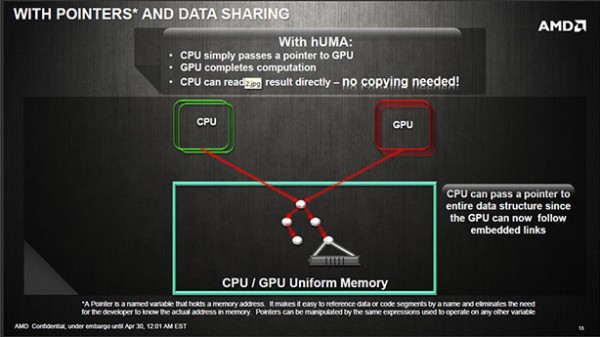
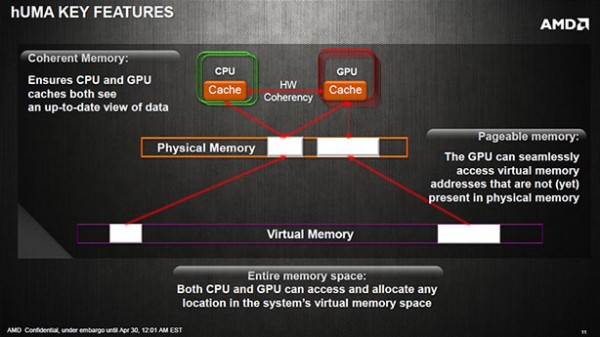
hUMA, o lo que viene siendo «heterogeneus Uniform Memory Access», consiste en unificar la memoria del CPU y GPU, modificando su arquitectura para adaptarla a una HSA (Heterogeneus System Architecture).
Para tener una referencia de que supone ésto, os diremos que las vigentes Apus poseen dos tipos de memoria, una para el procesador en general y otra para los gráficos. hUMA precísamente busca que sea única, permitiendo el acceso de lectura y escritura a ambos procesadores (CPU y GPU) evitando cuello de botella y por tanto aumentando el rendimiento.
Los actuales procesadores pueden ejecutar tareas complejas con un montón de hilos de proceso y rápidamente, y por supuesto cuantos más núcleos tenga, más tareas podrá ejecutar. Por otro lado, las GPUs tienen miles de núcleos (Shaders) y son capaces de realizar tareas de forma simultánea en cientos de hilos de forma paralela, pero a diferencia de los procesadores CPU, éstas tareas tienen que ser independientes a las otras. Lo que HSA pretende hacer es que todo esté unificado en el mismo procesador, y que dependiendo de la tarea, ésta sea ejecutada en el CPU o en el GPU.
Aparte de los beneficios descritos hasta ahora, AMD destaca también ciertos beneficios de HSA:
Finalmente, se espera que el controlador de memoria hUMA sea DDR3-2133Mhz, de baja latencia y preparado para dar un buen ancho de banda a todo el sistema.
Por supuesto, algunos puntos ya forman parte de alguna arquitectura como CUDA, la cual emplea una capa de software para interpretar una entrada de programación y automáticamente manejar la complicación de la gestión de memoria, pero sin embargo HSA no requerirá de software alguno.
Como sabéis, HSA no es único de AMD, ya que gira en torno a la HSA Foundation, la cual la integran miembros como Samsung o ARM entre otros. También se sabe que la nueva consola de Sony, la Playstation 4, será de las primeras en integrar hUMA.
Bien, hasta aquí ha llegado la primera parte del artículo, compuesta por dos de las tres grandes novedades de la nueva y prometedora Apu de AMD, próximamente disfrutaremos de la segunda parte de éste pre – análisis donde conocemos a «Spectre«, la gráfica que integrará ésta Apu.
Amazon siempre tiene una gran cantidad de ofertas en todo tipo de productos, y los…
Después de los reportes de varias CPU de AMD quemadas, se acaba de reportar otro…
Intel ha anunciado que el proceso 18A acaba de entrar en "producción de riesgo", por…